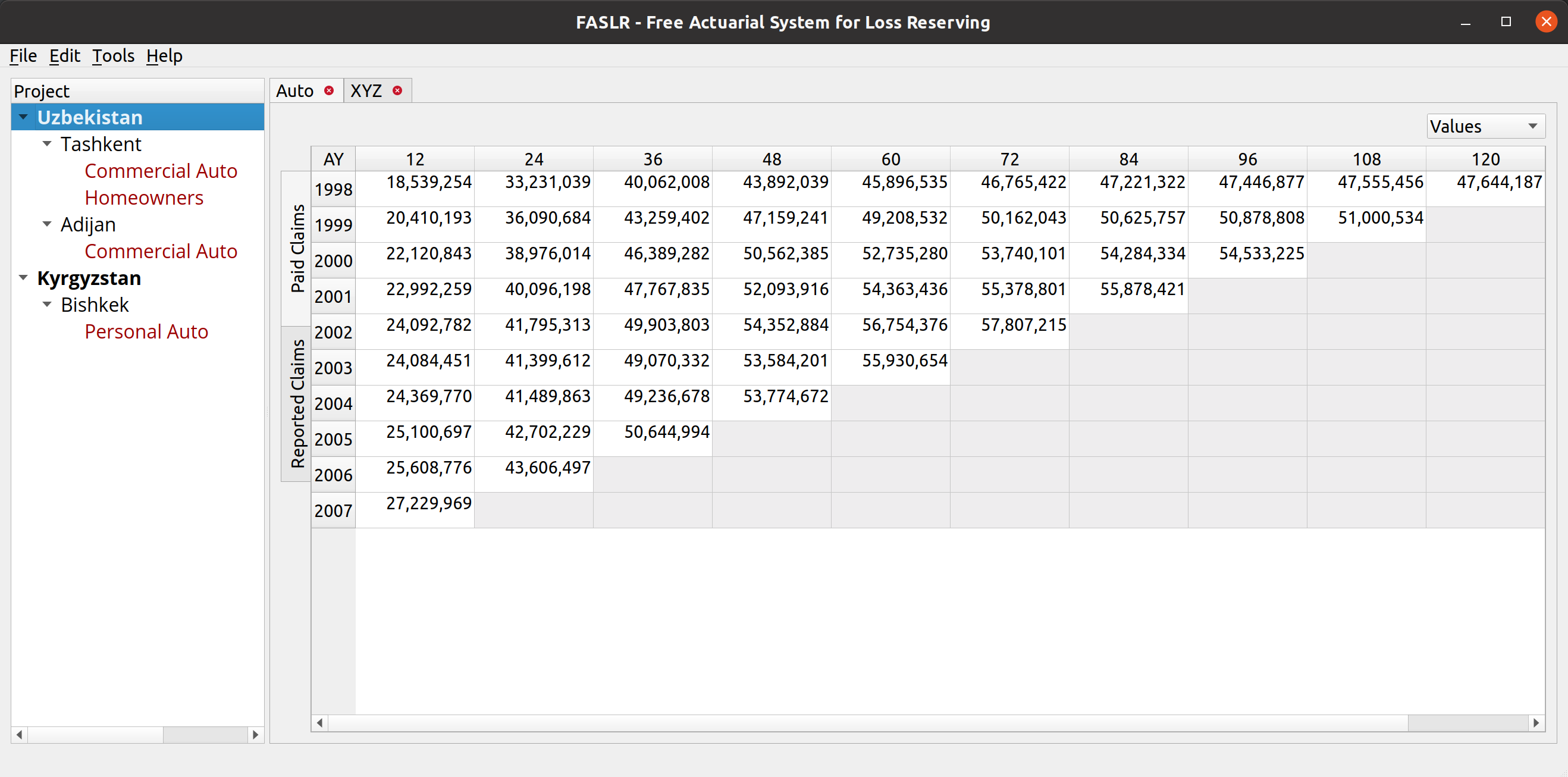
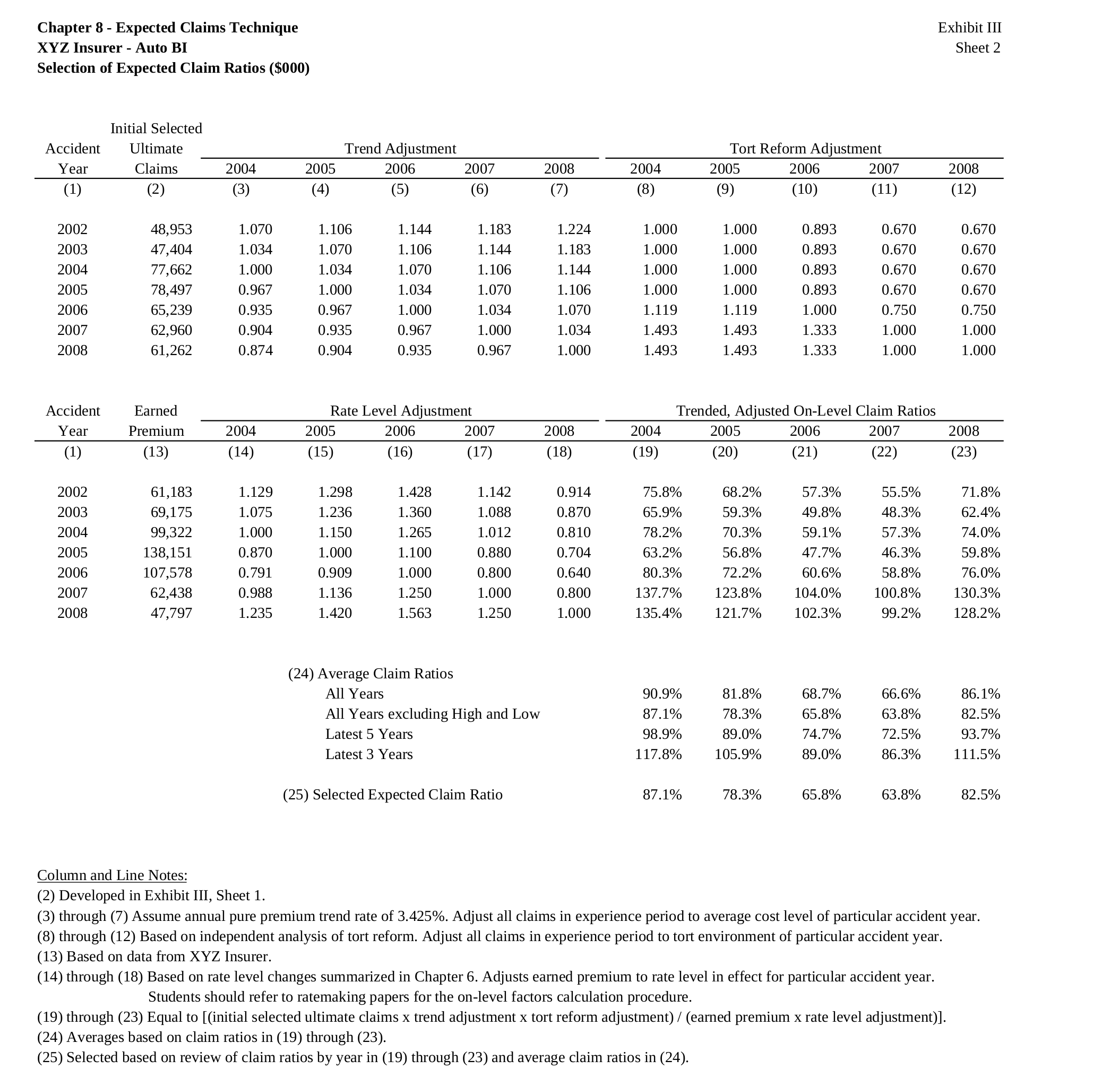
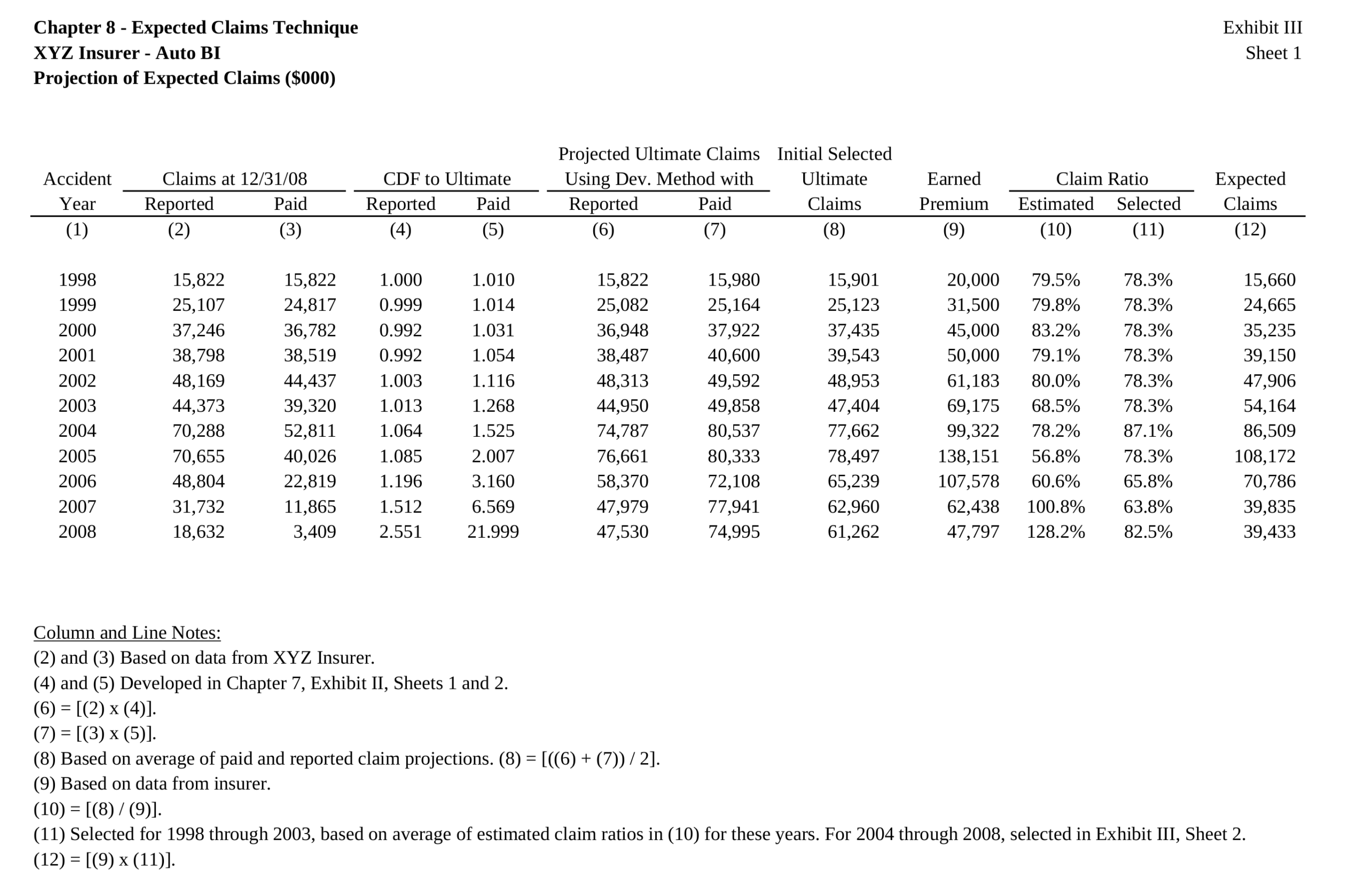
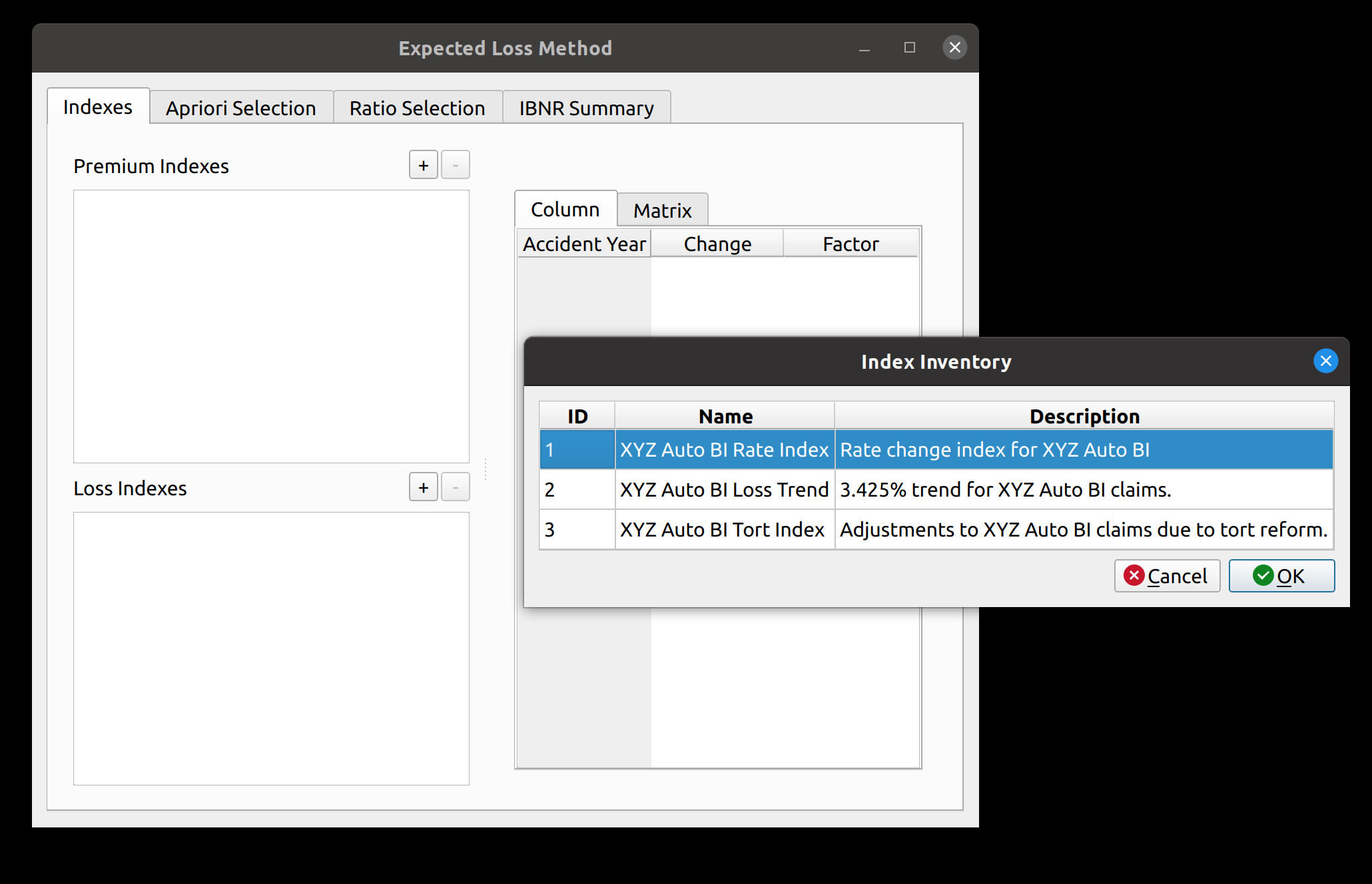
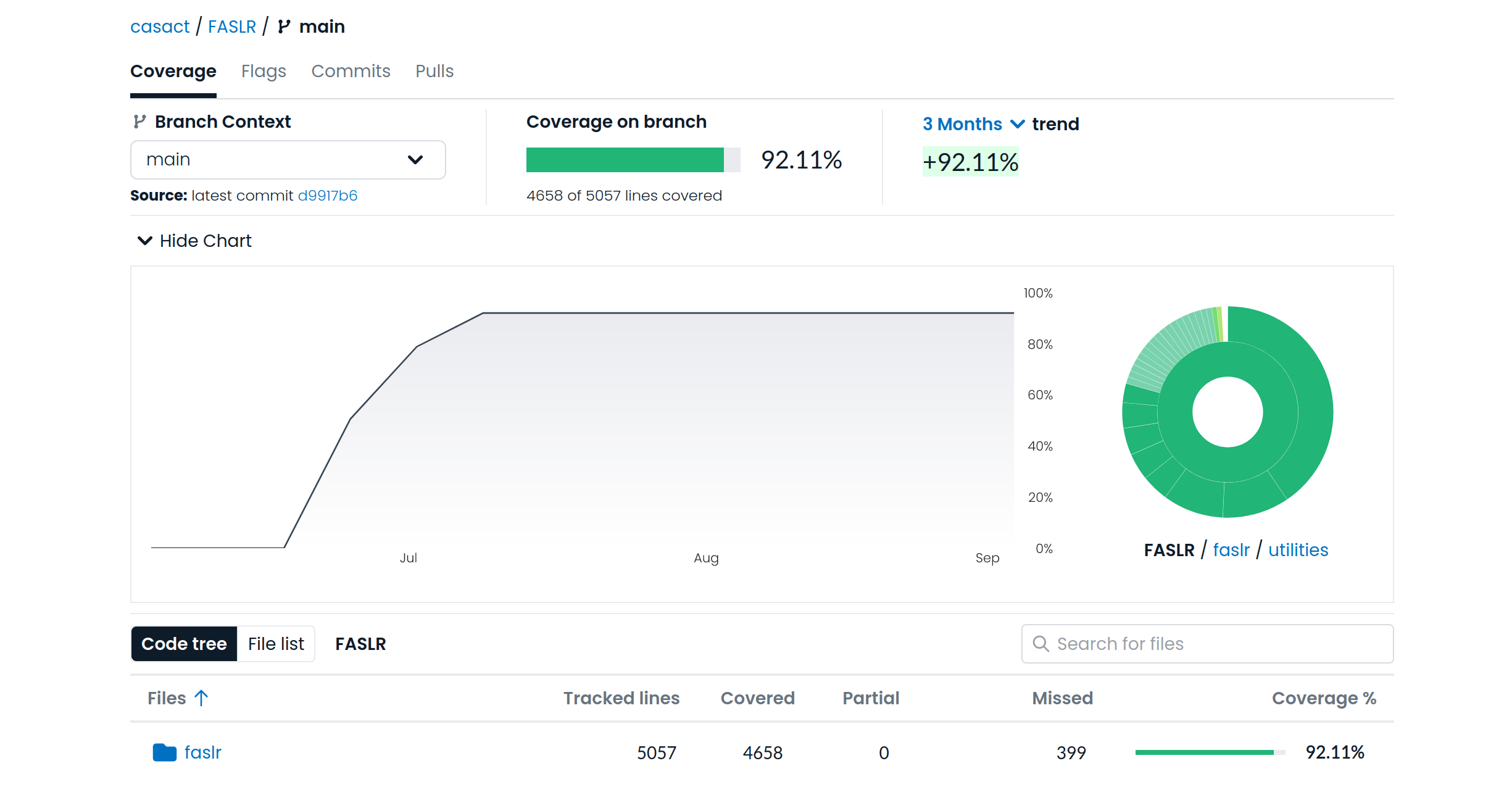
FASLR v0.0.9 adds a third reserving technique, the Bornhuetter-Ferguson technique. From a technical standpoint, there wasn’t much work beyond adding a few more columns to what I had done with the expected loss technique, namely the percentage unreported and unpaid losses that serve as the credibility weighting between the development and expected claims techniques – the two methods that underlie the Bornhuetter-Ferguson method. So in this blog post, I’ll focus on the engineering decisions that expedited the turnaround time on this release – three weeks as opposed to the many months it took to develop the base loss model from which the core FASLR reserving techniques derive. It is this base model that enables newer techniques and future extensions to be quickly developed.
If you are new to FASLR, it stands for Free Actuarial System for Loss Reserving. If you are more interested in discovering FASLR’s capabilities, you can browse previous posts about the project on this blog. You are also free to browse the source code on the CAS GitHub or view the documentation on the project’s website.
The Base Model Class
The development goals of the recent past and near future involve incorporating the basic reserving methods from the Friedland reserving paper into the FASLR application, namely:
- Chain Ladder
- Expected Loss
- Bornhuetter-Ferguson
- Benktander
- Cape Cod
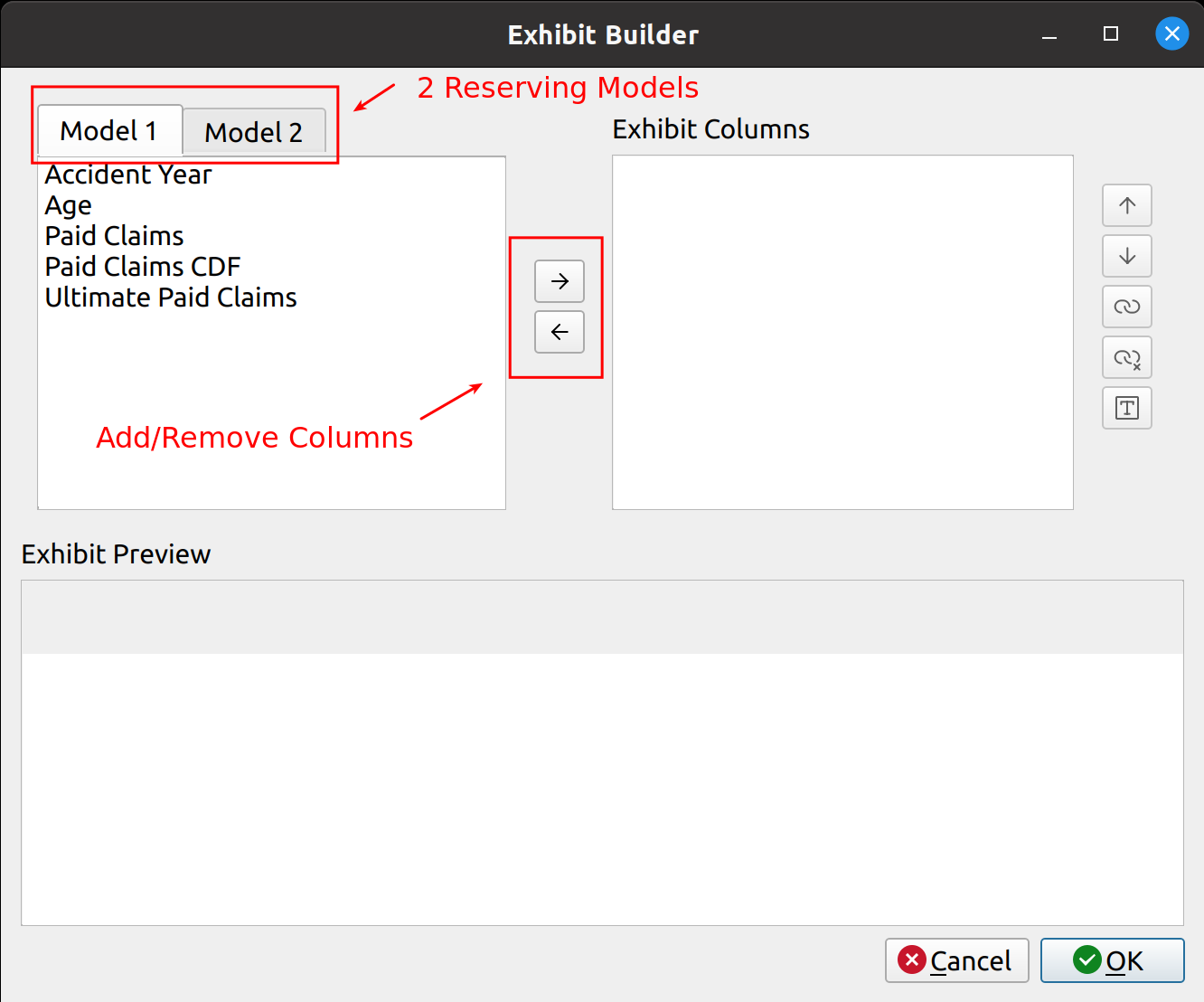
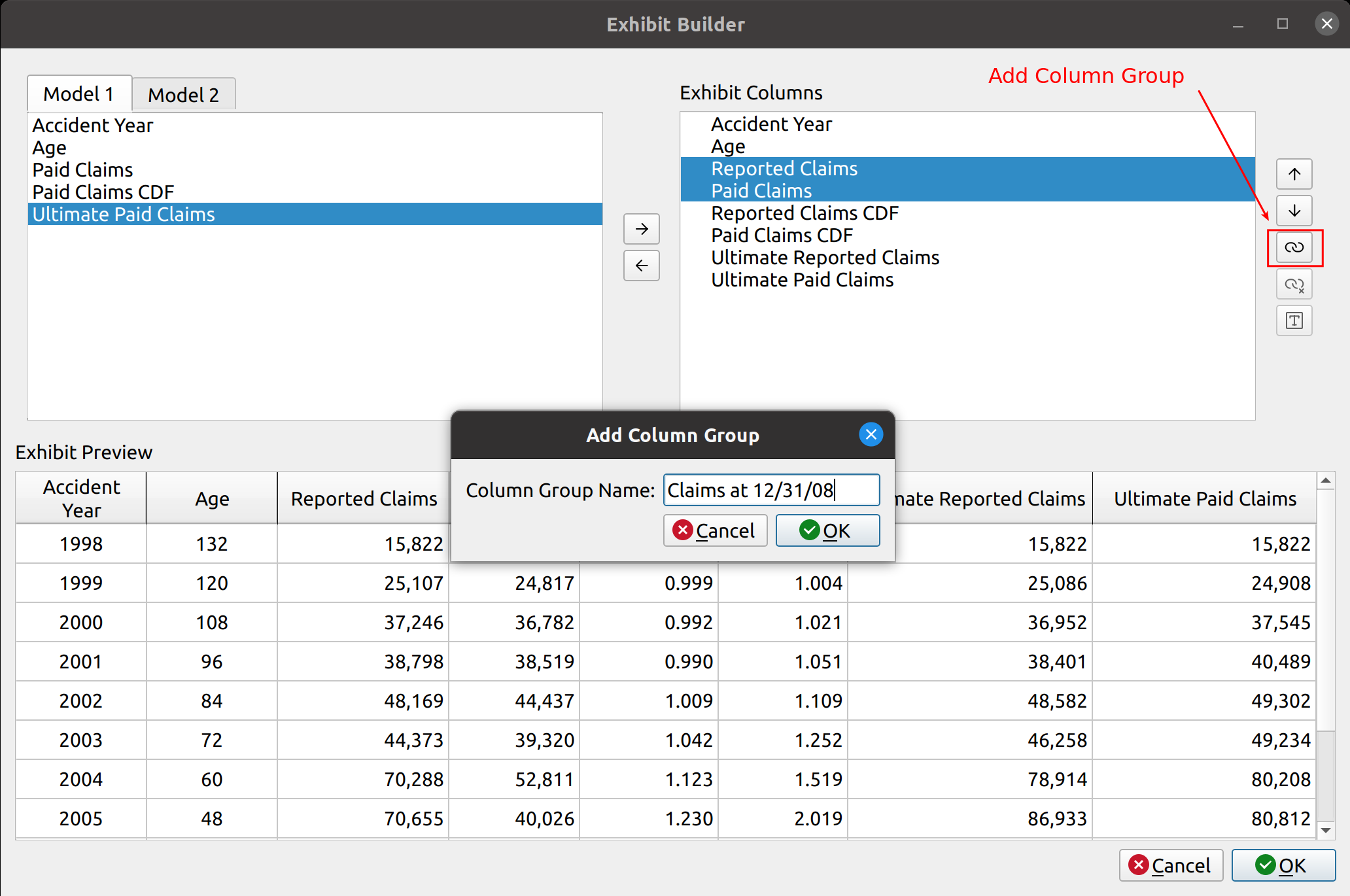
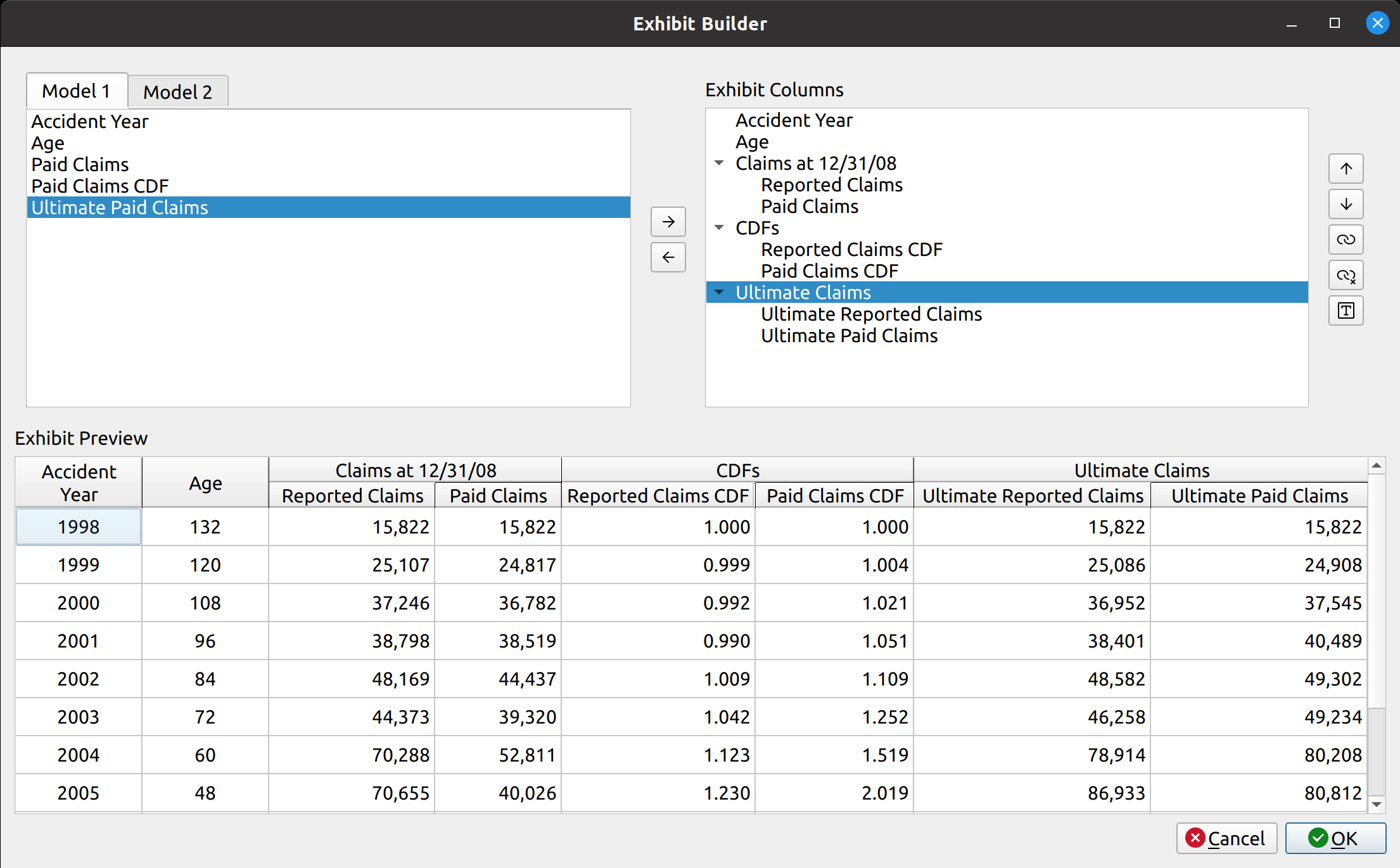
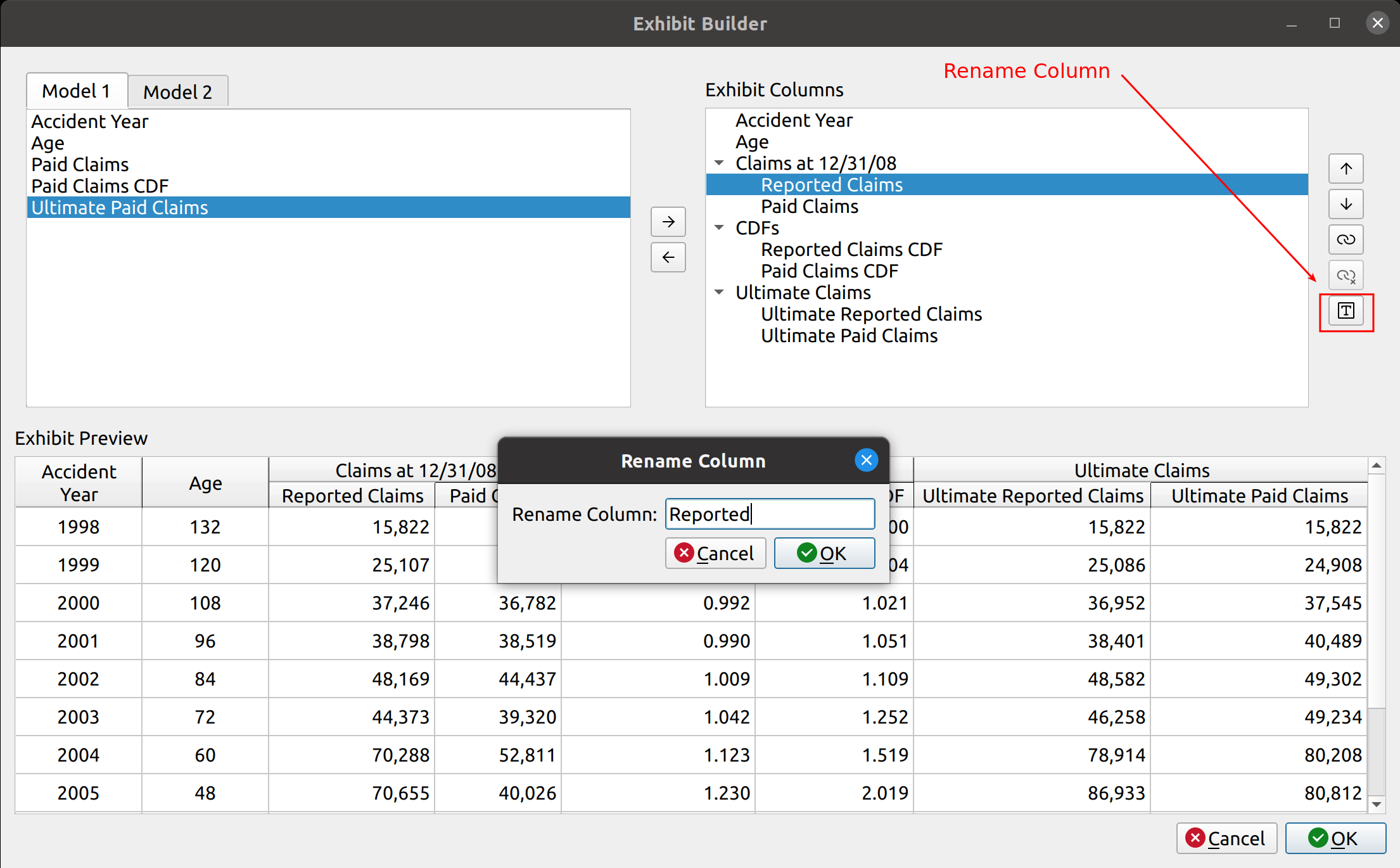
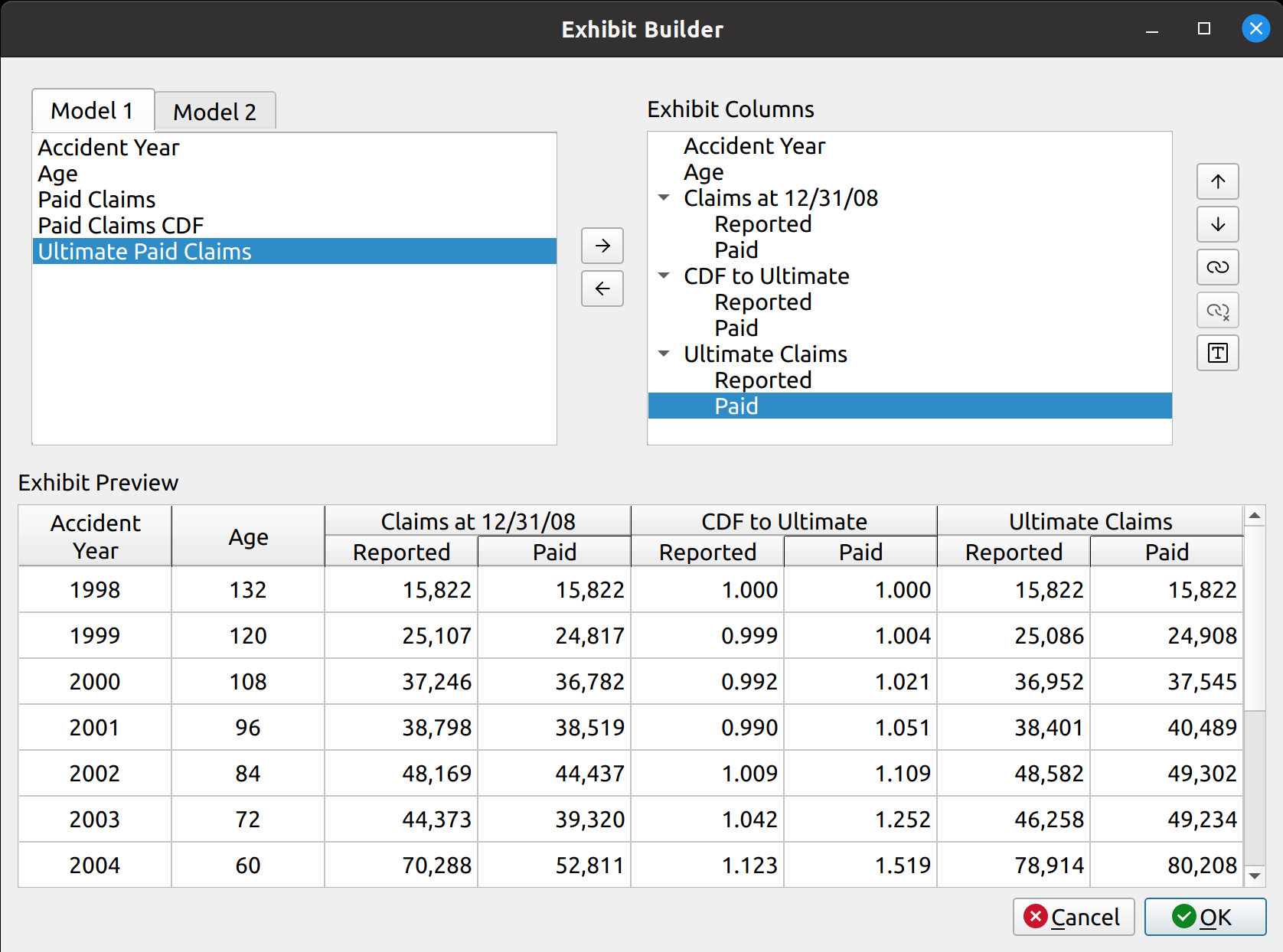
Creating the prototype for the chain ladder method was quick, mostly because it only involved the selection of the development factors and did not include features that are required for more advanced techniques such as trending, or summary exhibits such as IBNR and unpaid loss calculations. It became apparent by the time I worked on the Expected loss technique that not only would I need to create these new features, but also to engineer them in a way that allows them to be shared by the other models without having to recreate them from scratch every time. This would involve creating a base model class from which the other classes would inherit, speeding up development time and easing ongoing maintenance in the future. I hope this simple diagram shows you what I had in mind:

I’m not going to pretend I know the rules of any diagramming standards (I don’t), but I hope this one is simple enough for you to get the idea. The base model serves as a template from which other models derive, this includes features for:
- The display of loss triangles
- Trending of losses and premiums
- Selection of some kind of ratio (e.g., link or loss ratios)
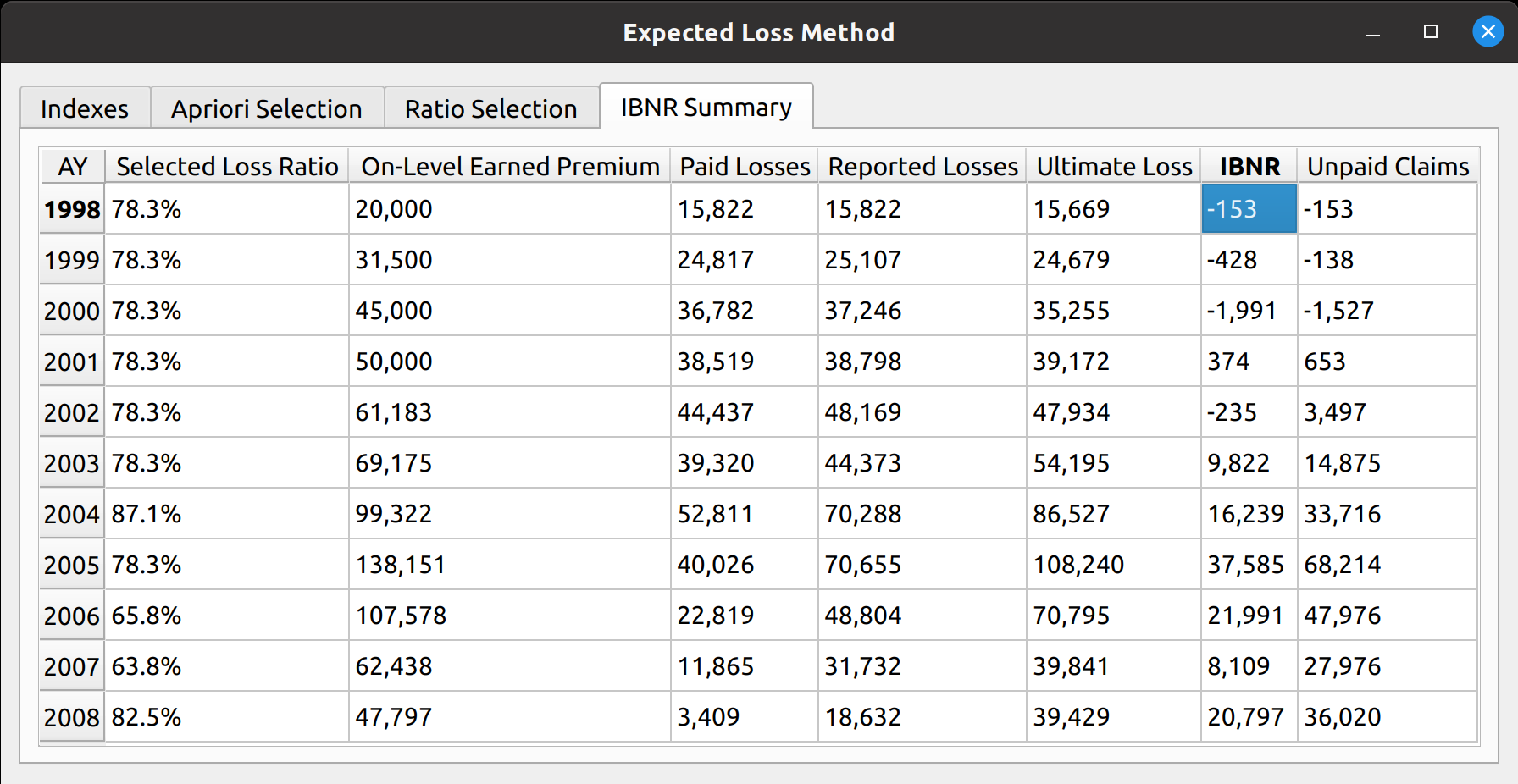
- Ultimate loss and IBNR summaries
These are listed to the right of the base model in the diagram. The models listed below inherit these features by default, although they can be overridden with model-specific tweaks. For example, the chain ladder technique involves the selection of link ratios whereas the expected loss and other techniques involve the selection of both link and loss ratios. Furthermore, model-specific features are listed below the models, like how the Bornhuetter-Ferguson technique adds a credibility calculation using unpaid and unreported loss percentages.
The Ratio Selection Model
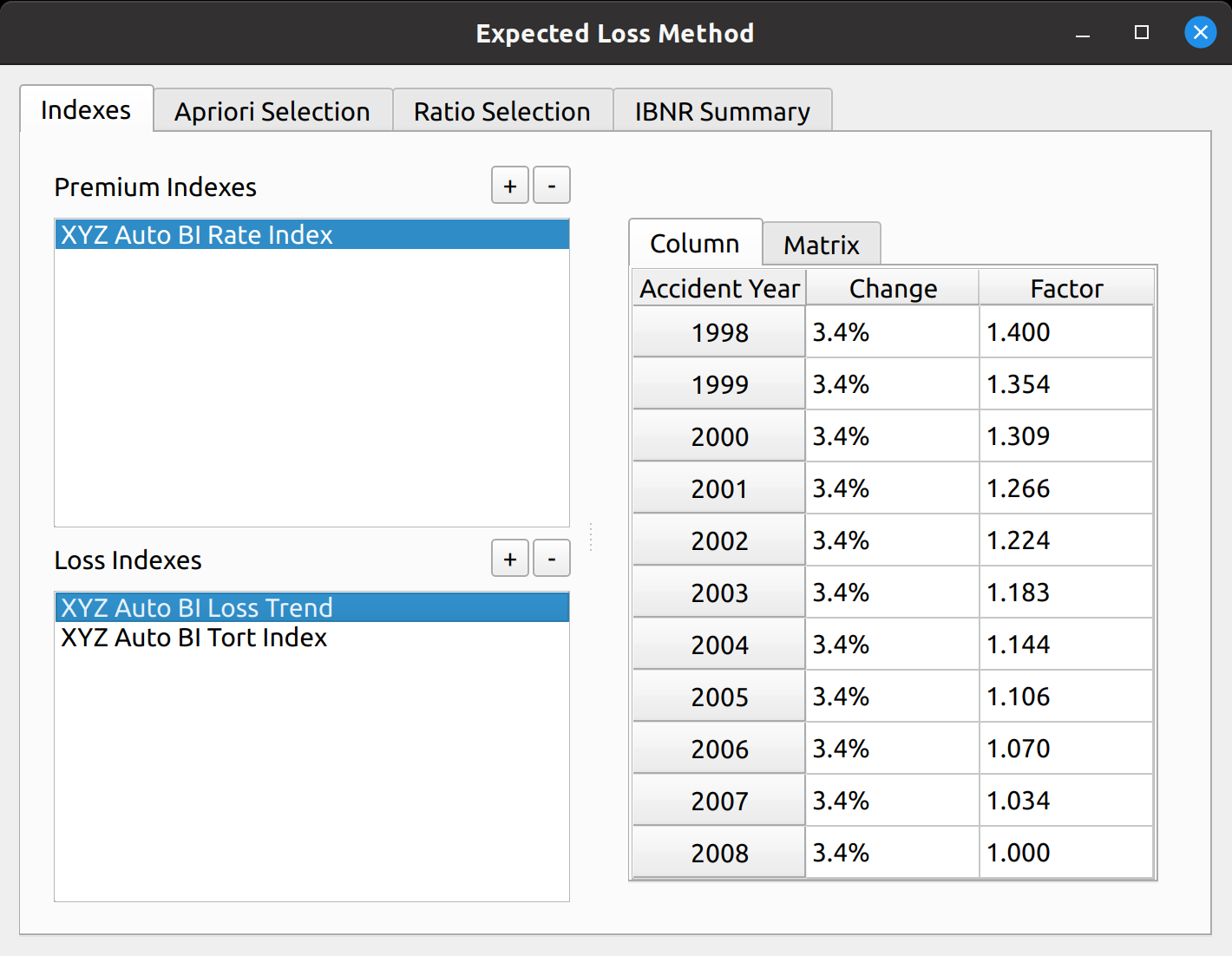
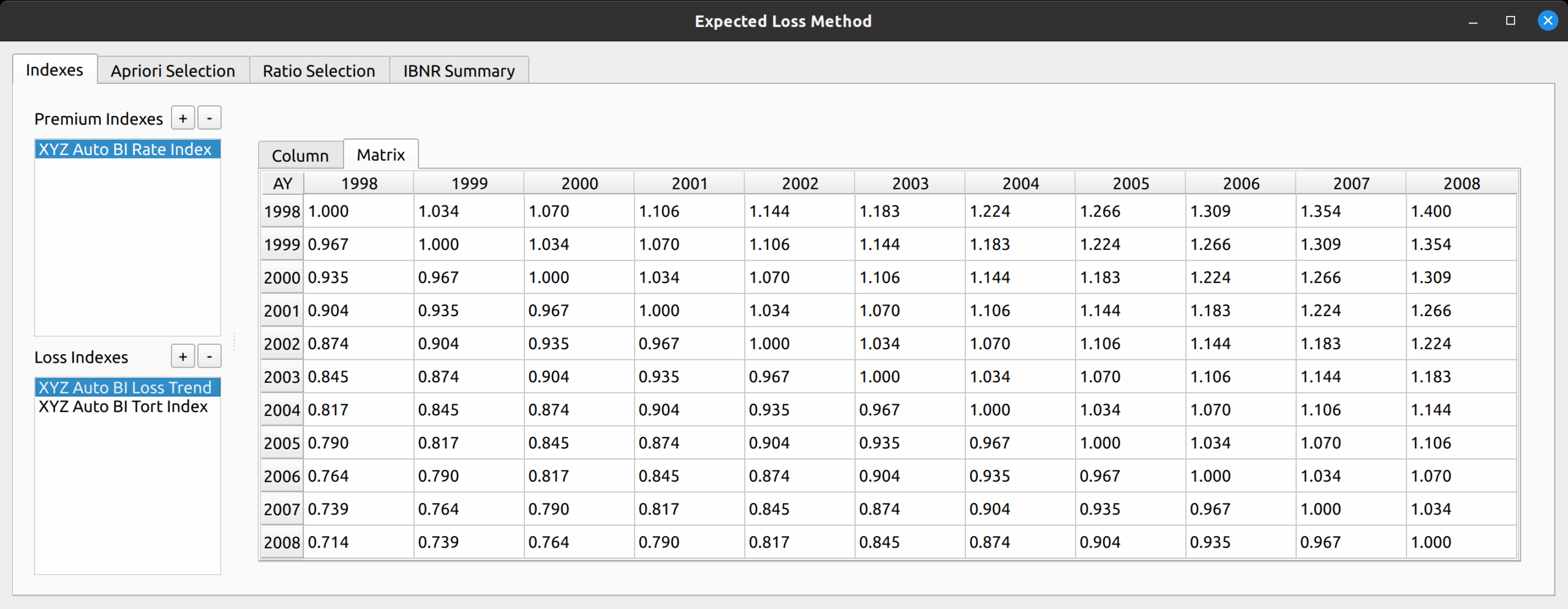
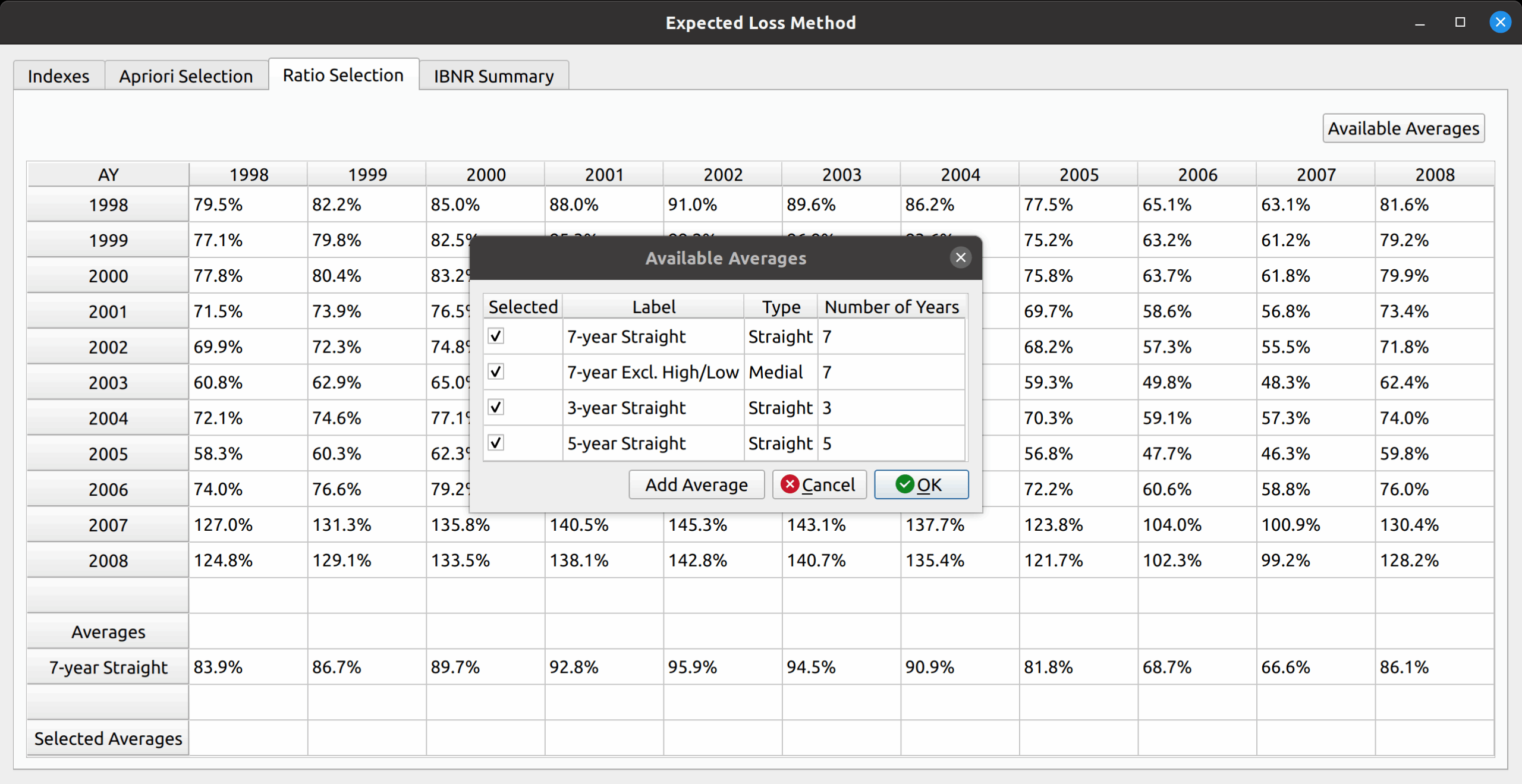
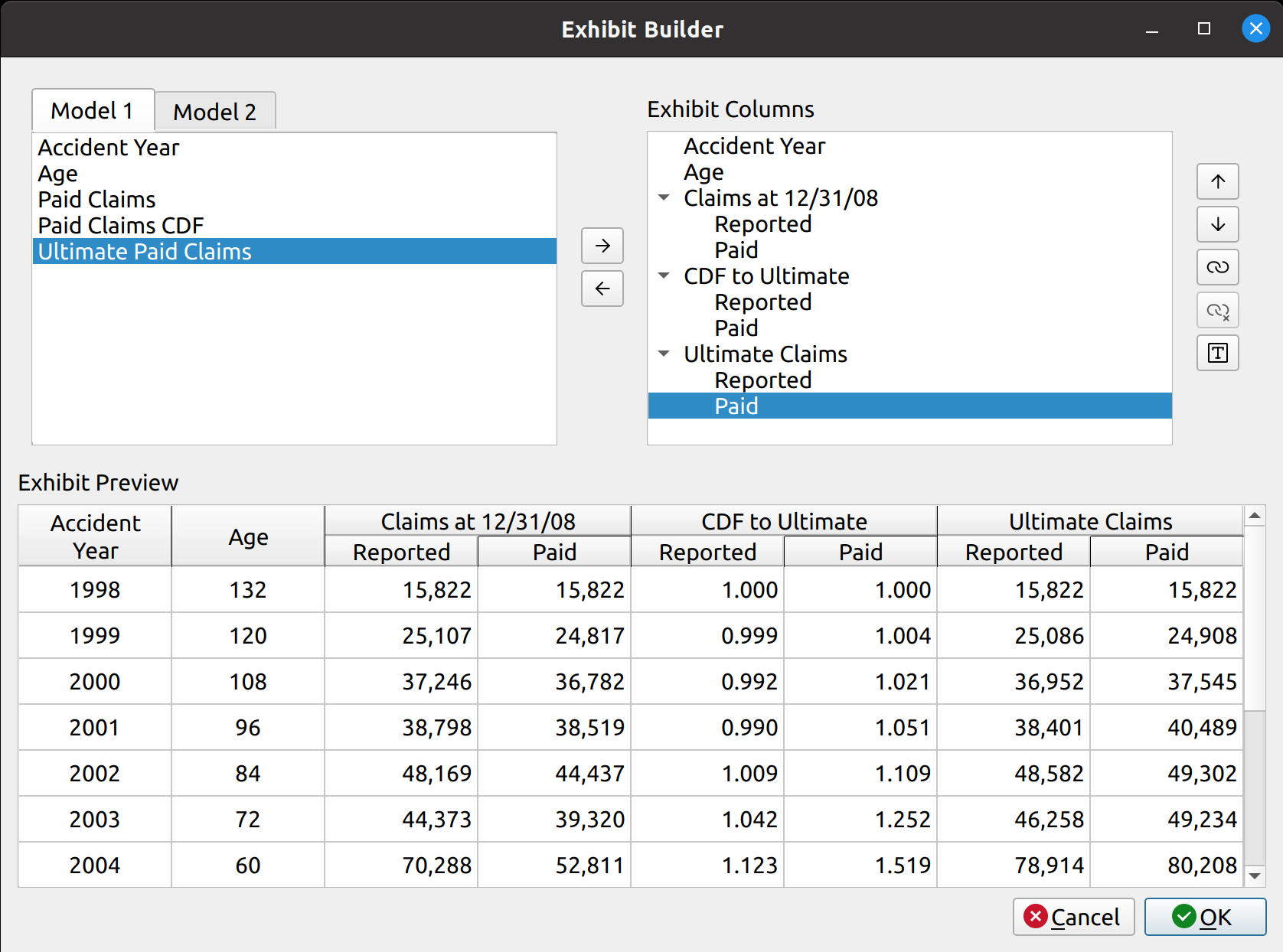
At the heart of the base model is the selection of ratios. This can be any kind of ratio, such as link ratios in the chain ladder method or loss ratios in the expected loss method. Below is a picture of the bare bones, base ratio selection model.
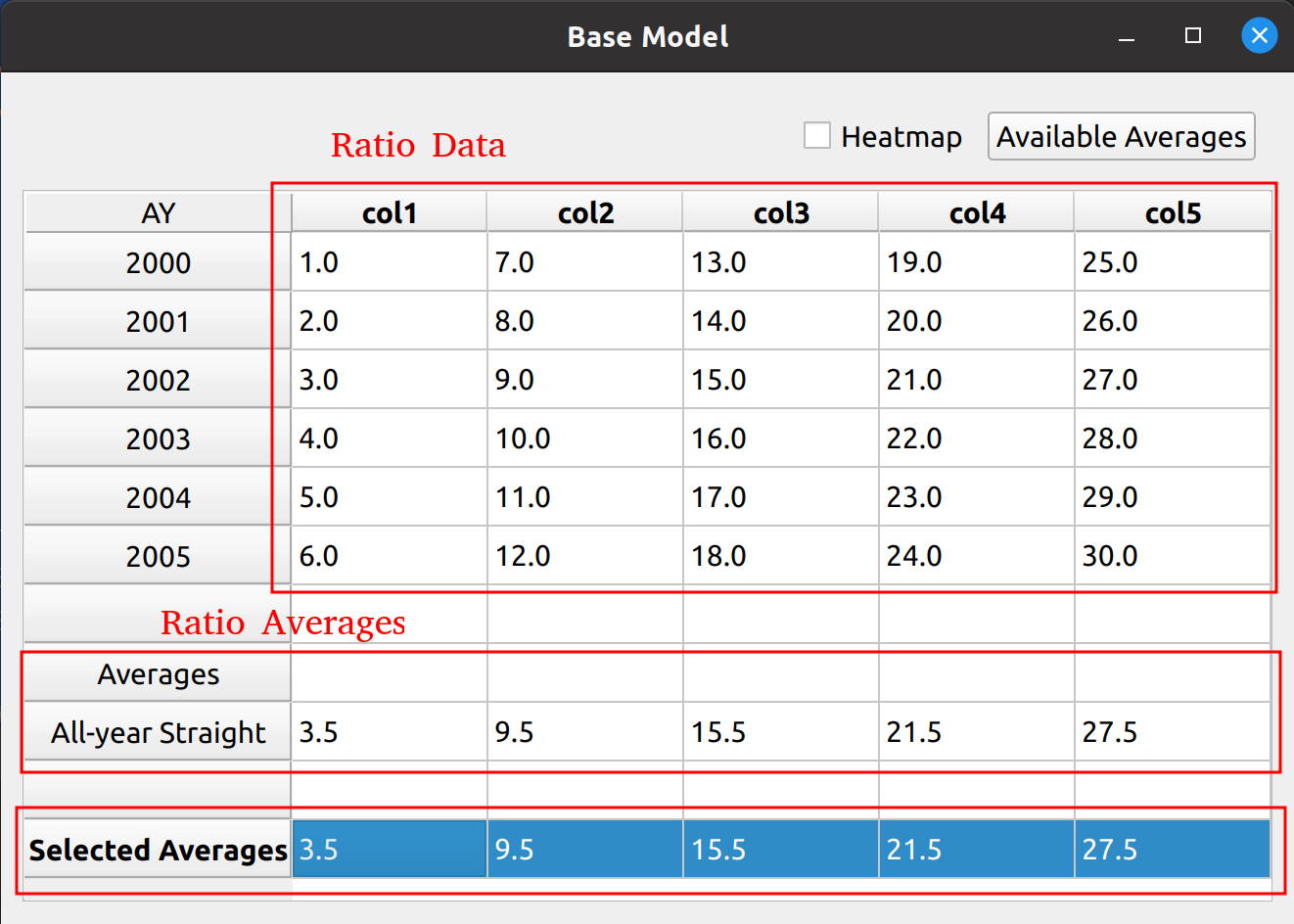
You can see that the data don’t mean anything, as the base model alone cannot serve as a true reserving model – method specific tweaks are required. In a way, putting nonsense data as a placeholder will serve to demonstrate the base model’s flexibility in being used by the inheriting reserving models. You can see the features from this base model image that will be found in the inheriting models, such as:
- A toolbox at the top to toggle a heatmap and add average types
- A DataFrame in the middle to hold ratio data
- A section below the DataFrame to calculate averages common to various models (i.e., volume-weighted, straight, etc.)
- A section holding the selected averages
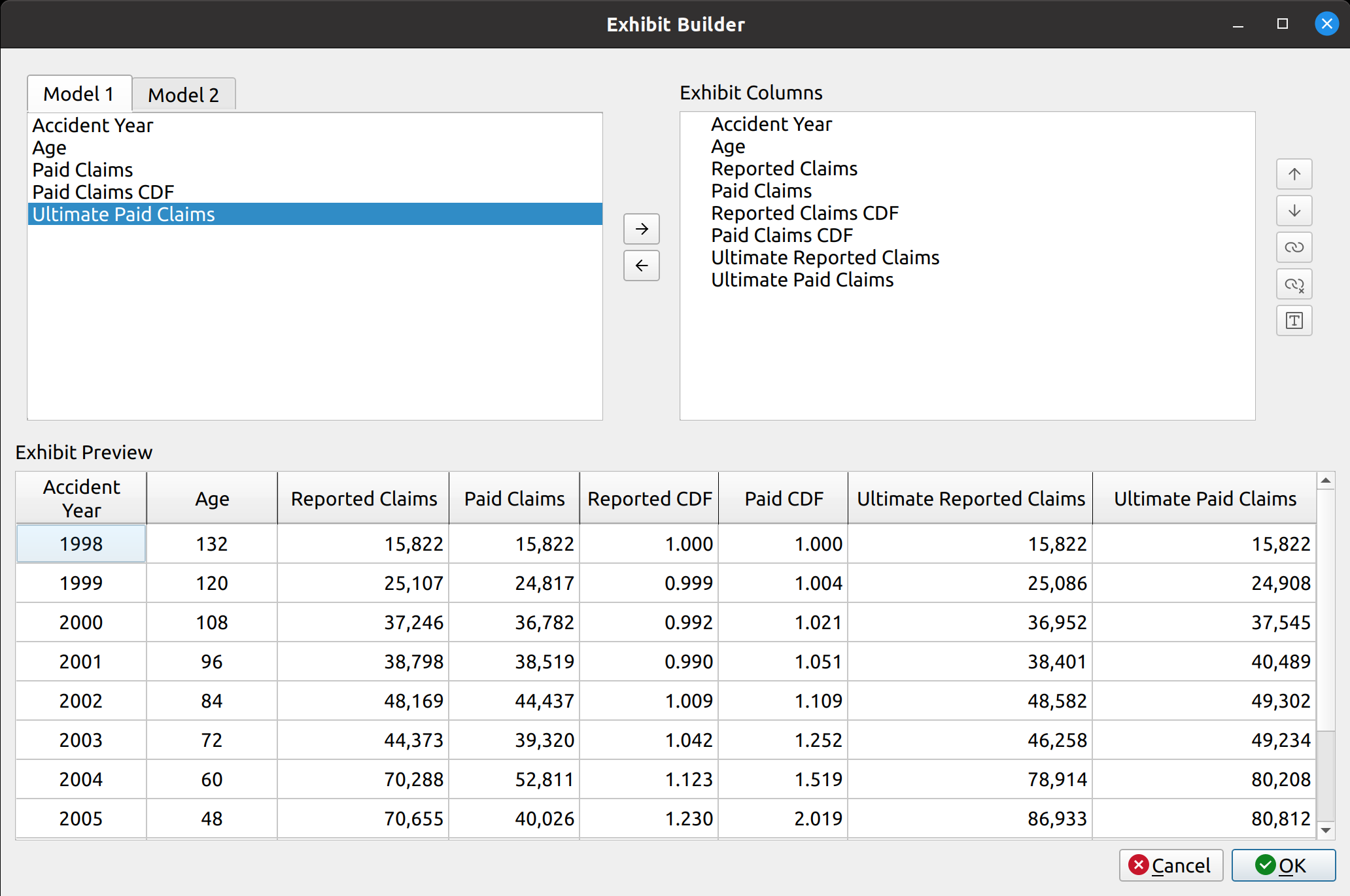
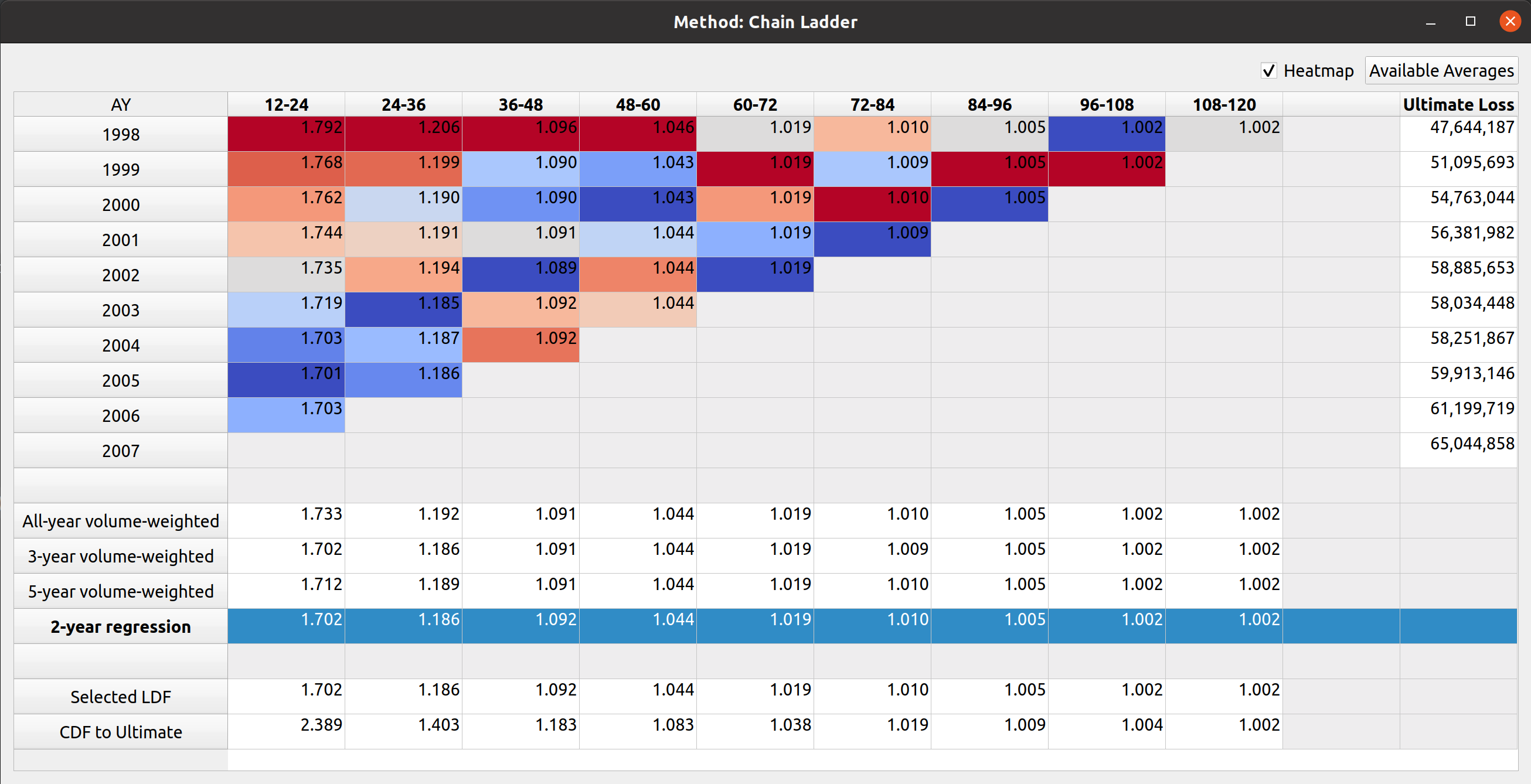
An example of the Chain Ladder model, which inherits from the base model, shows the heatmap feature applied as well as an auxiliary ultimate loss column:
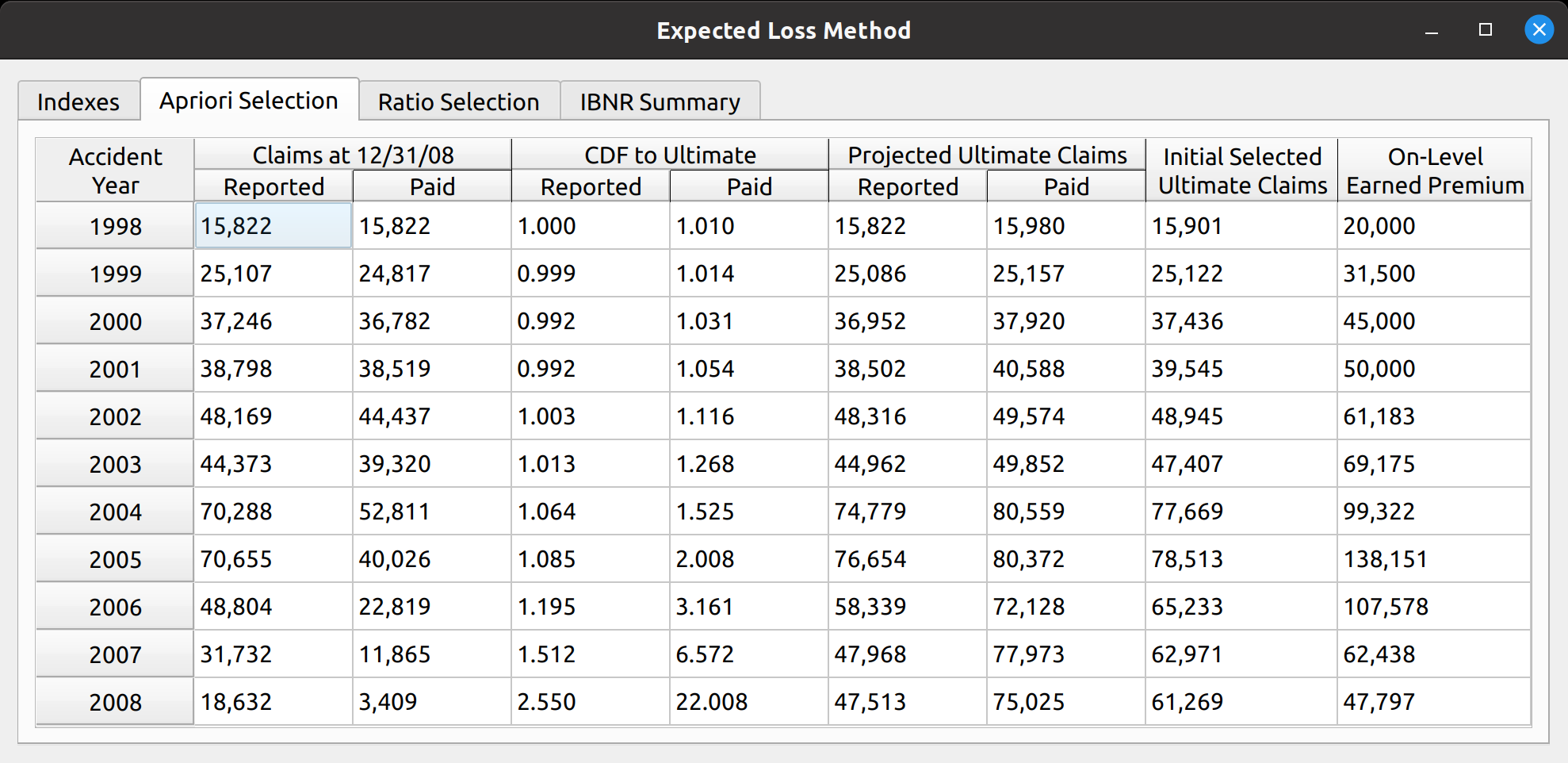
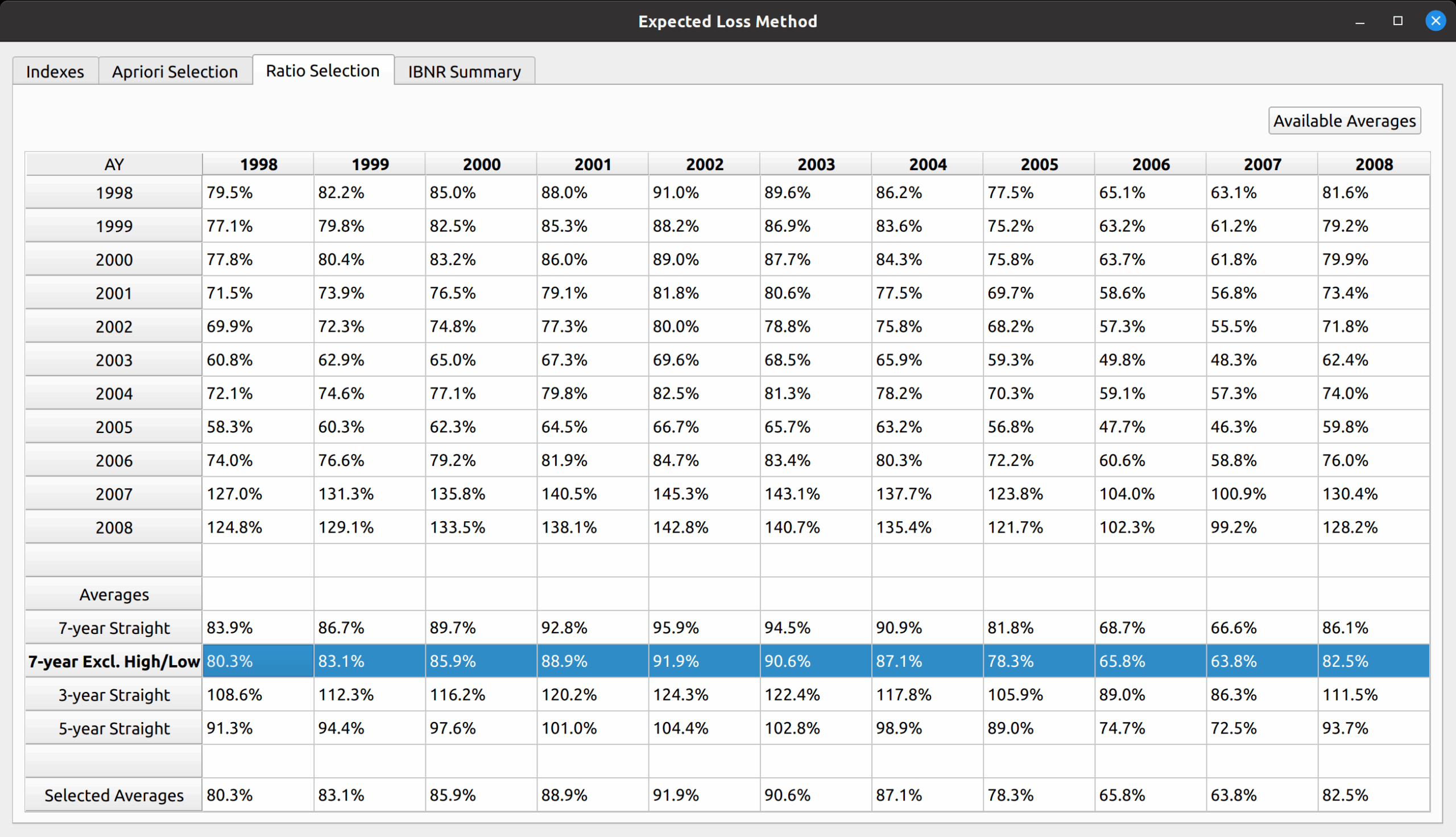
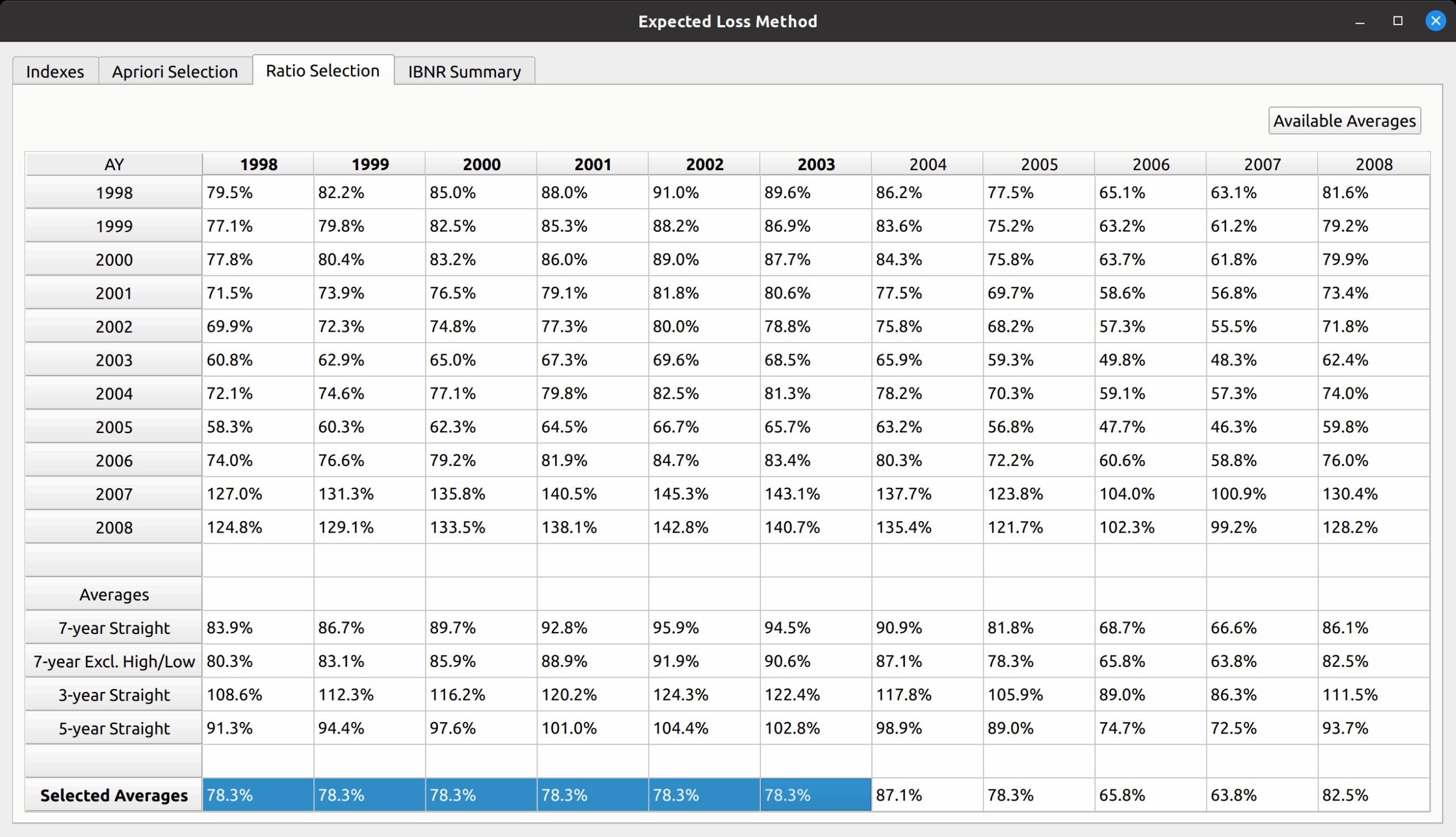
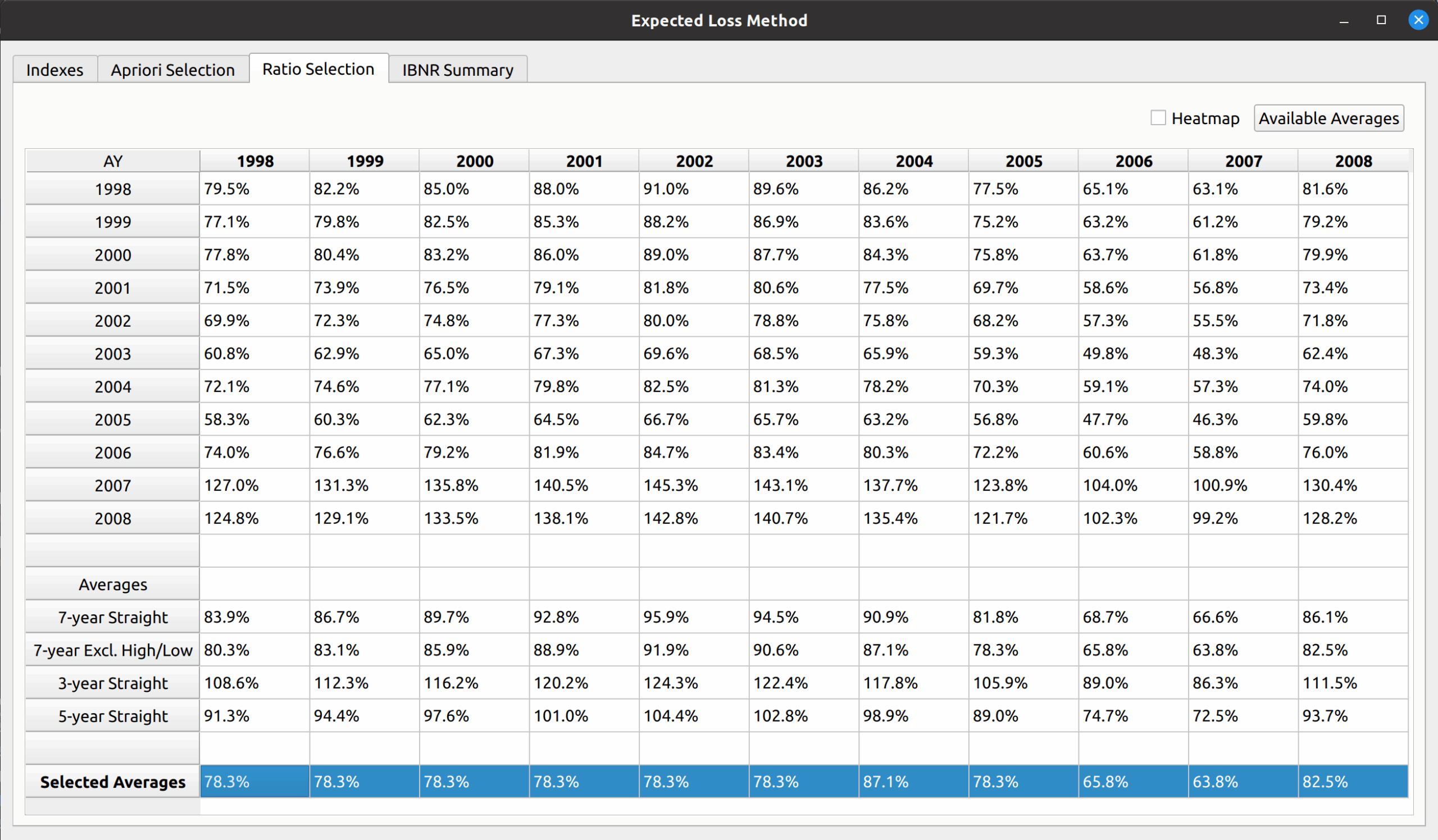
Another example is the expected loss model, which replaces the DataFrame with loss ratios instead of link ratios, and you can see that all the main sections described in the base model are still preserved:
Extensibility
A key motivation for the base model is to enable FASLR to accept custom user extensions. Due to the vast array of insurance products, and the nuances of the different reserving practices used between actuaries, it is impossible for an out-of-the box application to meet all the needs of all the users. By providing a base model class with a standard API, the user will be able to create their own subclasses of the base model, which will be accepted by FASLR so long as key aspects of the standard API remain intact.
For example, an actuary may have their own unique way of calculating expected claims to be used in the Borhnhuetter-Ferguson technique that is not offered by default in FASLR. If they create their own version of the base model, and match the API for exporting things like ultimate losses, they will be able to incorporate it into FASLR as a custom extension.
The Bornhuetter-Ferguson Widget
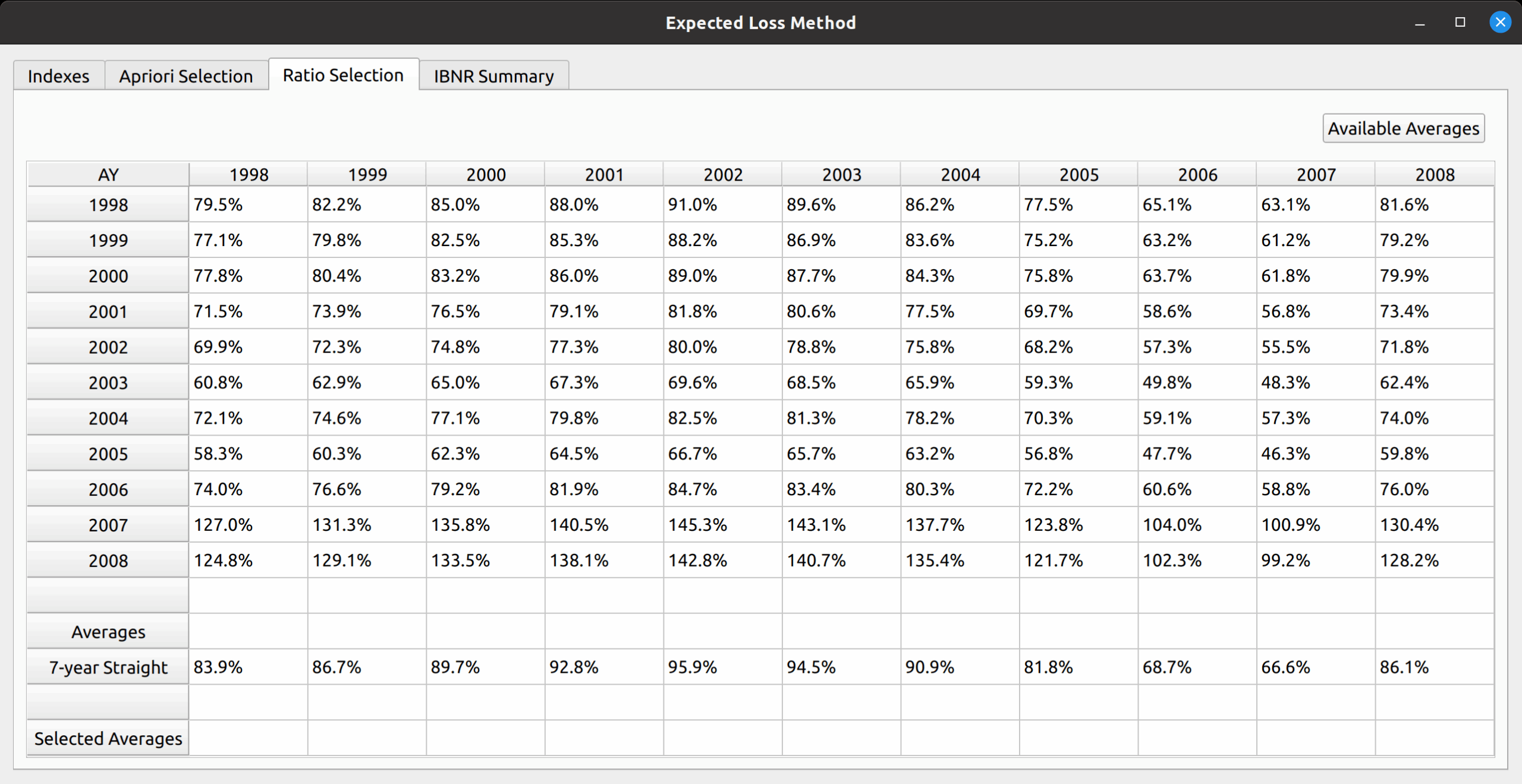
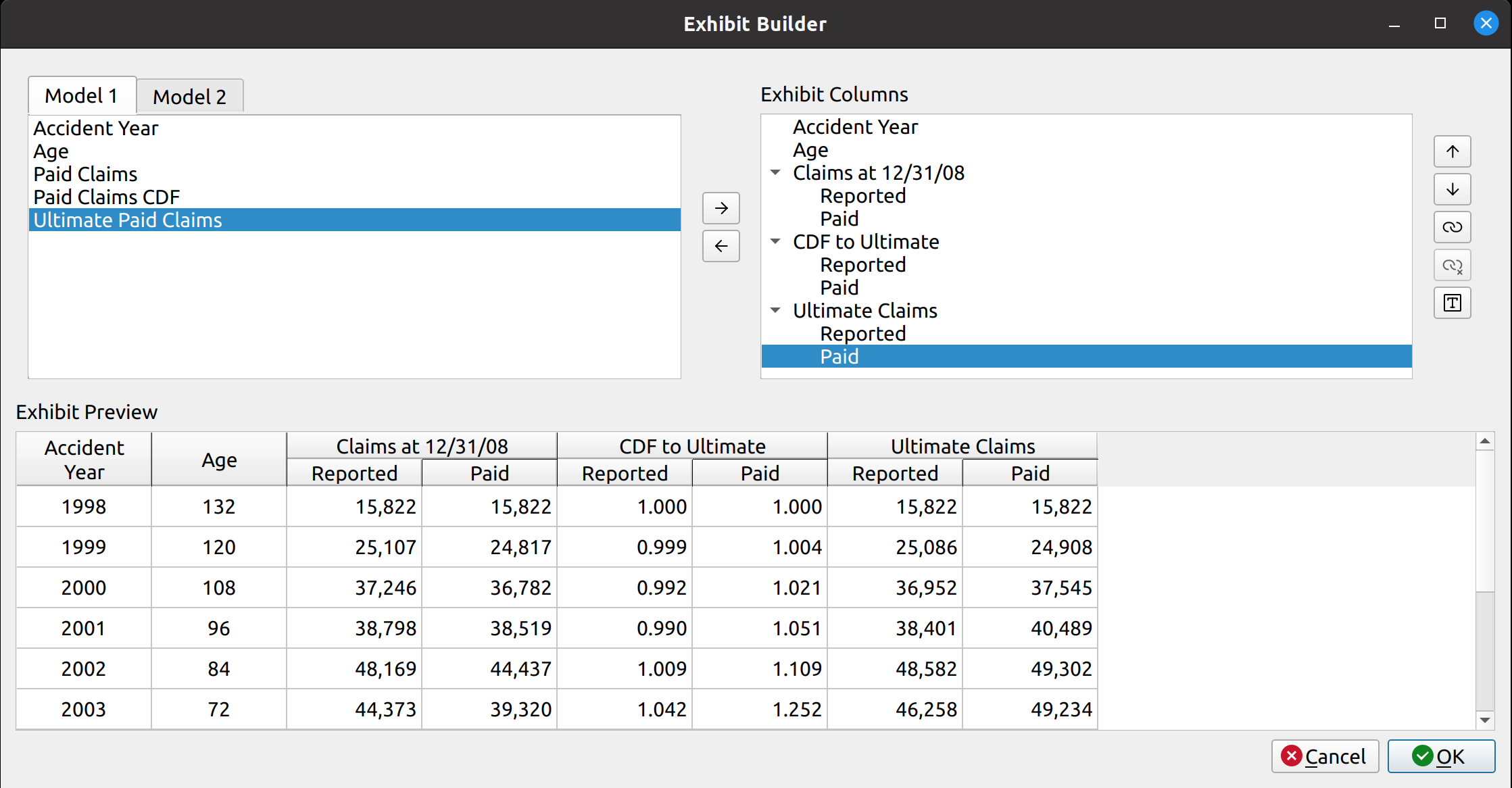
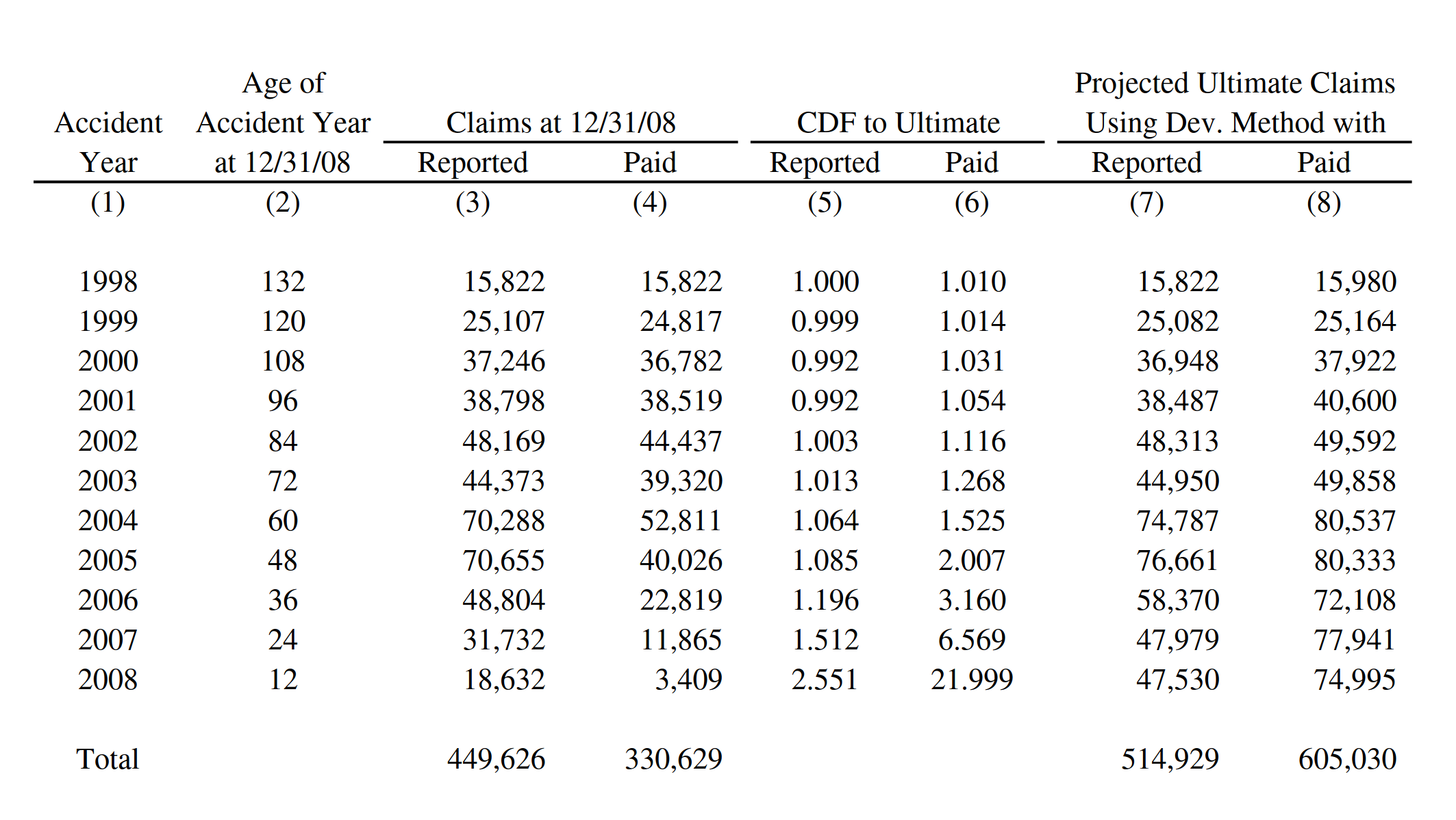
The next test of base model is to see if the Bornhuetter-Ferguson widget can inherit the features from the base model, and then incorporate the credibility calculations. In this example, we seek to replicate the XYZ Auto example from Friedland:


The widget is displayed below. The model uses almost all the features of the expected loss model: indexes an apriori selection of ultimate losses, and a selection of expected claims (note that my values differ slightly due to different rounding practices).