I mentioned a few weeks ago that I’m spending about 30 minutes each day reading material that’s beyond my technical level of understanding. I‘ve been reading Data Mining at a rate of about 10 pages per day, with a strict limit of no more than 3 minutes per page. The first couple of chapters were pretty easy – they covered some of the basic goals of machine learning, such as pattern recognition and classification. The third chapter was a bit more technical than the first two, and now that I’m on the fourth chapter, I feel almost completely lost, especially when trying to understand the examples covering unfamiliar concepts like information theory and entropy.
There are few benefits to reading unfamiliar material – I think by doing so you’ll get a good idea of the subject’s prerequisites. In the case of data mining, I’ve learned that I’ll need to look in to algorithms and information theory. There were also some paragraphs that covered Bayesian statistics, which I studied last year but have gotten a bit rusty at – however, the inclusion of the subject indicates that I ought to review it if I want to have a deep understanding of how data mining works.
Data mining has some direct applications to actuarial work. For example, insurance companies need to divide policyholders into subsets and price the policies based on shared attributes amongst the policyholders in each subset. An example of this practice would be to charge the owner of a commercial supertanker a higher premium for a commercial shipping policy than the owner of a small tugboat. This is because the supertanker has a larger expected loss than the tugboat. This type of segmentation is currently done using a combination of basic statistics and business judgement (marketing, operating costs, etc.). Segmentation is easy when you think of extreme examples, like the one I just pointed out (based on size), however it becomes more difficult when you include other attributes such as age, manufacturer, where the ship is predominantly moored, and the climate of the geographic region where the ship travels on business. There might be significant overlap amongst individual ships regarding these categories, which makes classification difficult. In addition to the problem on how to classify ships, you also have the dilemma of choosing the optimal number of categories, the optimal size of each category, and the boundaries of each category.
Data mining aims to resolve this issue by quickly scanning large datasets and looking for similarities amongst ships that an actuary or underwriter would otherwise miss via traditional methods. Data mining isn’t widely used in the industry, but it’s quickly gaining ground as the rapid expansion in data-collecting technology has made such efforts feasible. I think it has the potential to significantly change the industry with respect to the way insurers price policies, and this is why I’ve become interested in the field.
I think data mining also has some very interesting applications in biology – for instance, you might remember learning about animal kingdoms back in grade school. I myself was taught that there were five, but nowadays a 6-kingdom classification system is popular in U.S. biology classrooms (some advocate for even more kingdoms). Taxonomy, which includes grouping organisms into kingdoms, as well as into separate species, is a problem that can be addressed with data mining. The following diagram looks as if the person who made it was trying to divide a dataset into two categories:
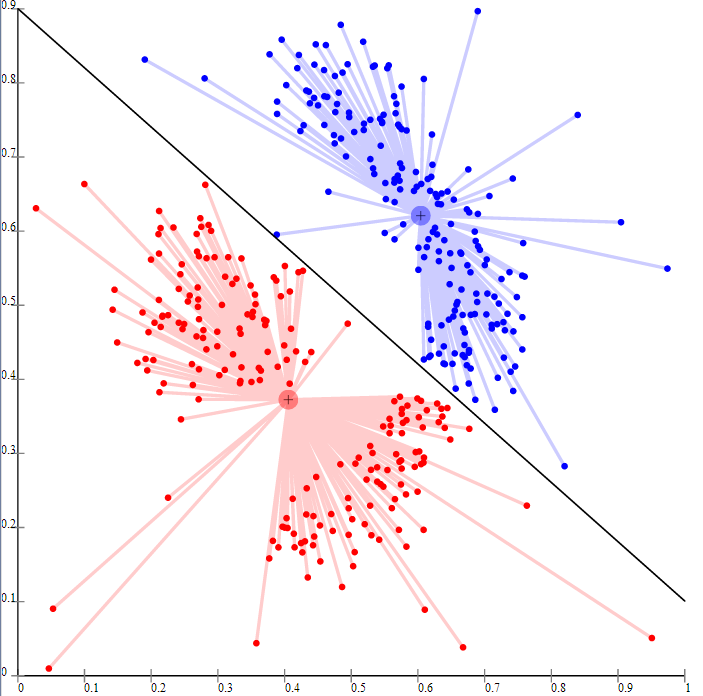 This reminded me of a case example in the Data Mining book on whether or not a dataset of flowers should be divided into two separate categories. The above image isn’t the same thing (although it looks similar to the graphic in the book), I just thought it was a pretty image that would look nice with this blog post. Apparently, the image is the result of a failed attempt at k-means clustering (I’m not going to pretend that I know what it means).
This reminded me of a case example in the Data Mining book on whether or not a dataset of flowers should be divided into two separate categories. The above image isn’t the same thing (although it looks similar to the graphic in the book), I just thought it was a pretty image that would look nice with this blog post. Apparently, the image is the result of a failed attempt at k-means clustering (I’m not going to pretend that I know what it means).
In the meantime I’ve been making some good progress in learning linear algebra, which is well within reach for me in terms of difficulty. I’ll also be going to a Houston Machine Learning Group meeting later this week, and if I find it interesting I’ll be writing about it here.
I took the Coursera Machine learning course a few years ago and I’ve been keeping an eye out for ML applications in P&C. Been disappointed, mostly.
In my experience insurance data sets tend to need more parameters and be too small for ML to add much value. In other words humans are better at using intuition than algorithms to analyze it. Considering that the intuition takes decades to build that’s a pretty damning statement on the power of ML for us.
Having said all that, I don’t work on homeowners or auto too much (mostly specialty lines stuff) so my experience is definitely biased.
I take it you work in specialty lines? I’m in that area – it’s been challenging working with small datasets but I do like the work. Sometimes when I don’t see the patterns I like I’m not sure if it’s because the data isn’t credible enough, or if it’s due to a lack of statistics knowledge.
Anywhow, I’ll give it a shot with machine learning to see if anything comes up – I think in the worst case scenario if it doesn’t work out, I’ll at least have learned something cool!