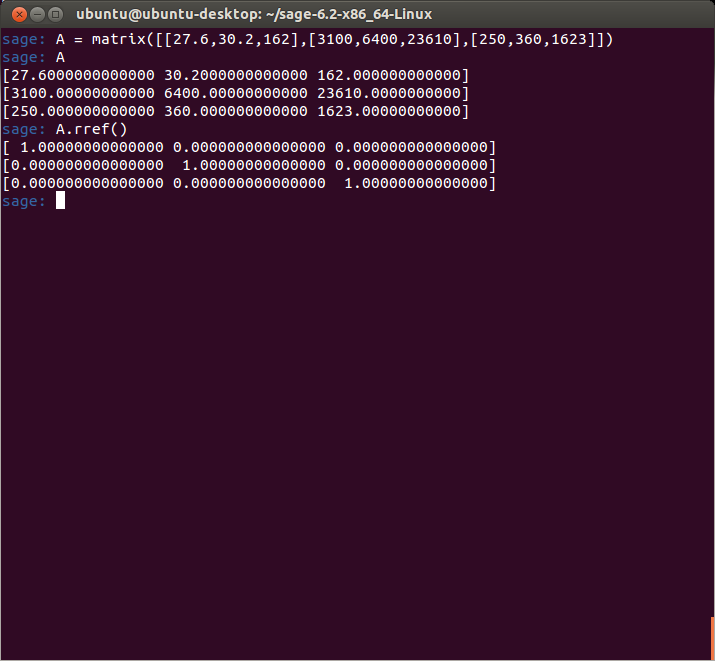
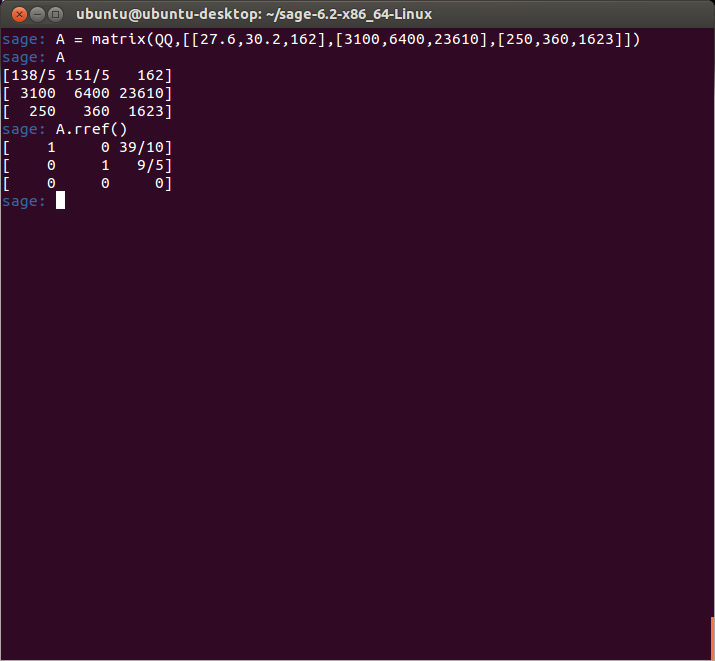
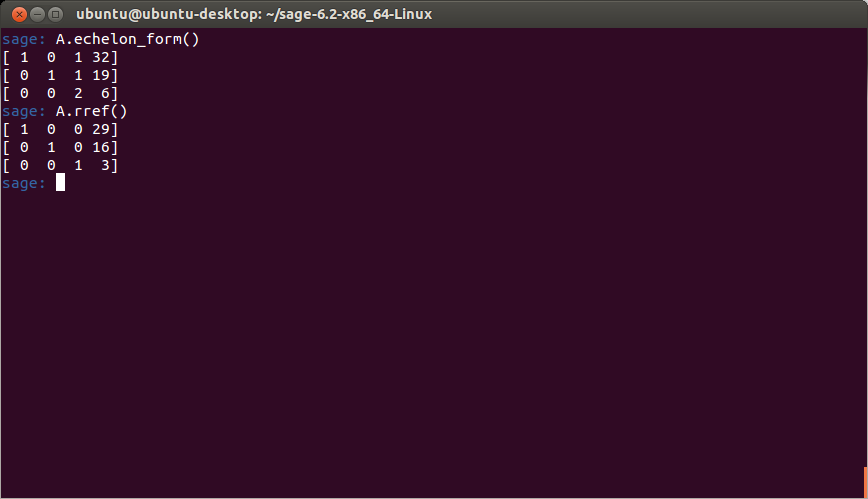
So, (as some of you already know) I had to temporarily halt my 70 Days of Linear Algebra because I had to attend to some extremely important matters over the last few weeks involving some big life changes, but all for a good reason. The outcome is mostly good news, and part of it is that I passed my last actuarial exam which means I have just 4 exams left to go. I will announce the rest of the news later.
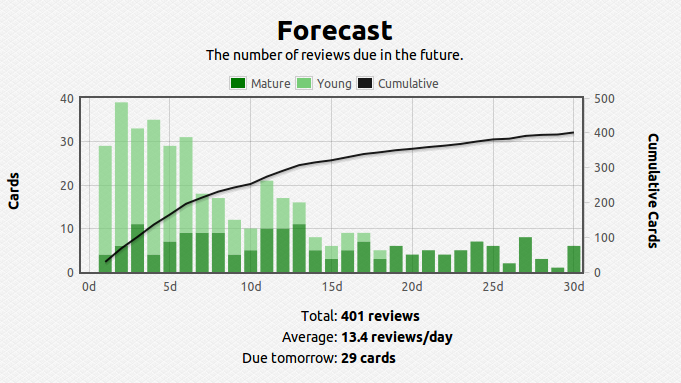
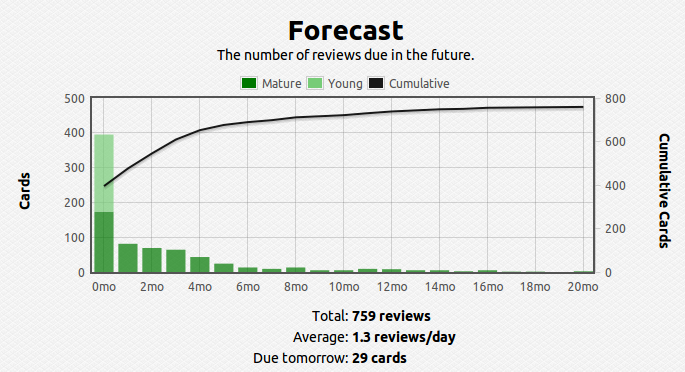
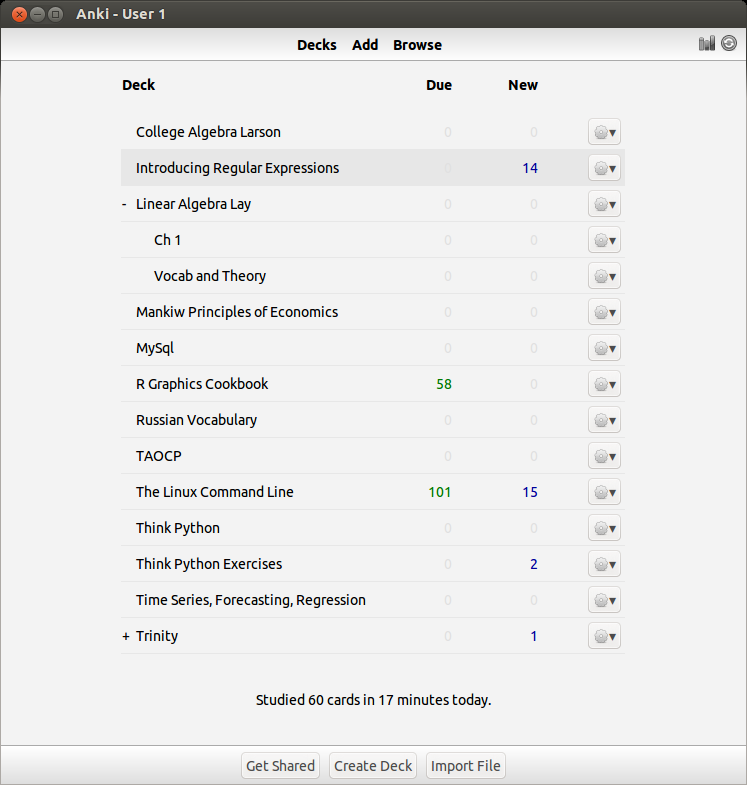
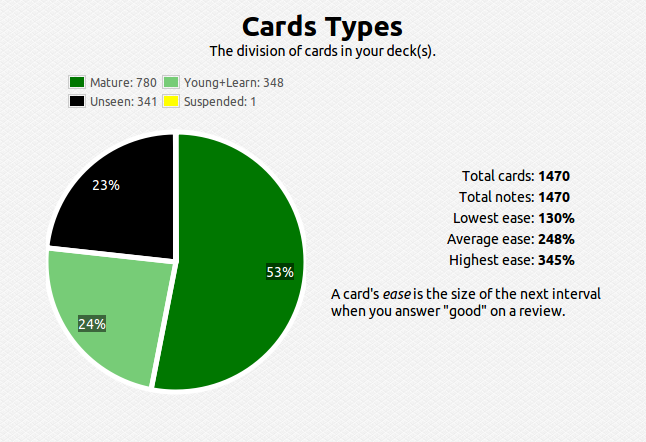
Anyway, I am happy to pick up right where I left off. I have been reviewing my notes using the spaced-repetition techniques I had outlined earlier, so my memory should be fresh.