Hello,
Today I’d like to give a brief update on some of the things I’ve been working on over the past few months, and perhaps briefly cover some projects that I’ve planned for myself for the upcoming year.
Networks
A few months back, an actuary contacted me and asked me if I wanted to study network analysis. I had looked into the subject a year ago and even bought some books (Networks by Mark Newman and Networks, Crowds, and Markets by Easley and Kleinberg), but never got around to reading them. Last week, I finally started reading the Easly and Kleinberg text, and right now I’m in the early stages covering basic terminology.
In short, the study of networks is a combination of graph theory and game theory, and is used to study crowd behavior and things like conformity, political instability, epidemics, and market collapse. These things have interested people for some time as they are social phenomena that have, from time to time, led to social upheaval and destruction.
Visualization
Over the past decade, the amount of data that we have on social networks has grown exponentially, and so has computing power. This has now made the empirical analysis of networks, which was once impractically expensive and time-consuming, possible. I’ve initiated a project called hxgrd which will essentially serve as a platform for simulating discrete, turn-based behavior amongst crowds. I’ve only initialized the repository (I’ll talk more about this github project in another post), and I’m looking for some software that I can integrate into the platform to save me some time later on.
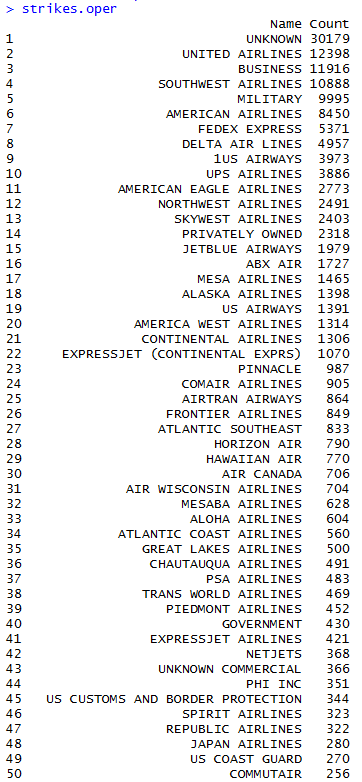
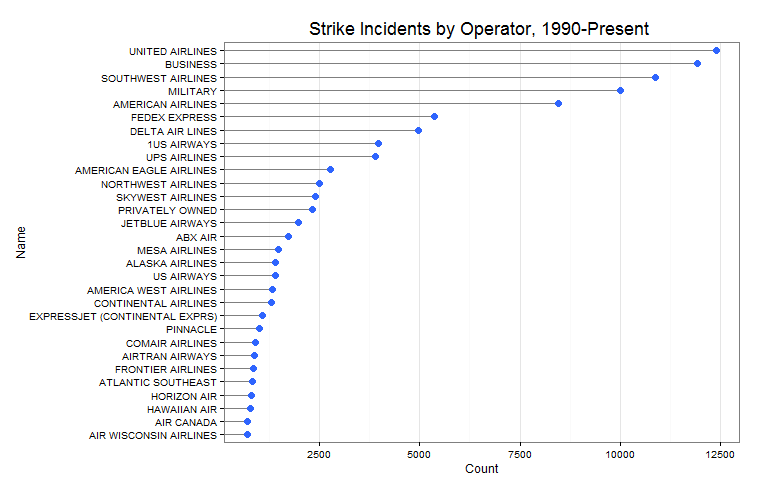
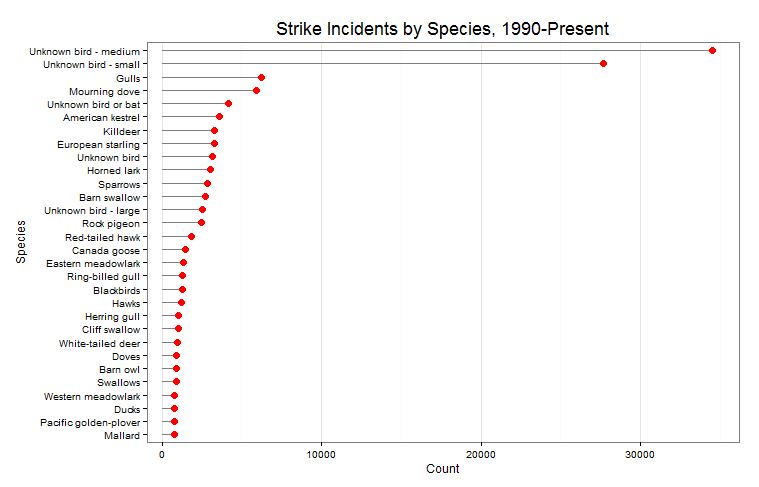
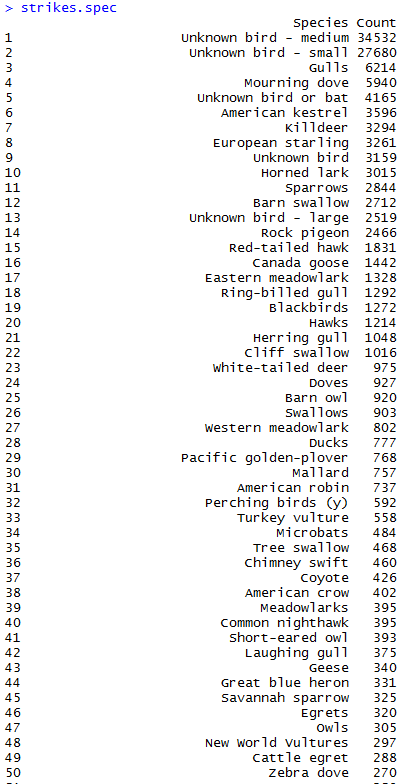
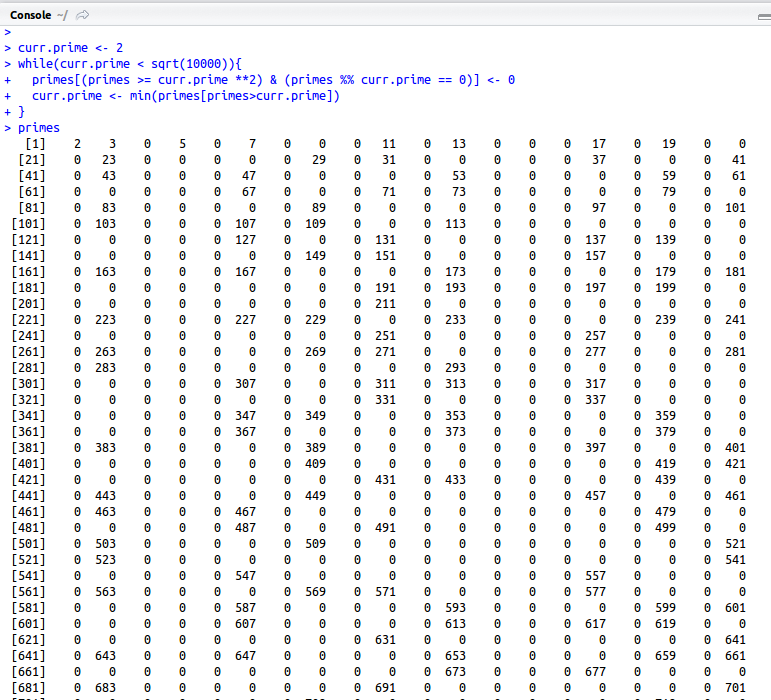
I stumbled accross a software called gephi which is an open-source tool used to visuzlize and analyze networks. I downloaded the program out of curiosity and went through their tutorial, which invovles visualizing the relationships between characters of Les Misérables (perhaps you have read the book or seen the musical). Here is a chart generated by gephi:

The graph consists of circles, called nodes, and lines connecting these nodes, called edges. Each circle represents a character that appears in the novel. Each line represents an association between characters. The size of the circles and names of the characters vary proportionally with the number of connections that a character has. As you can see here, Jean Valjean, the main character, has the greatest number of connections.
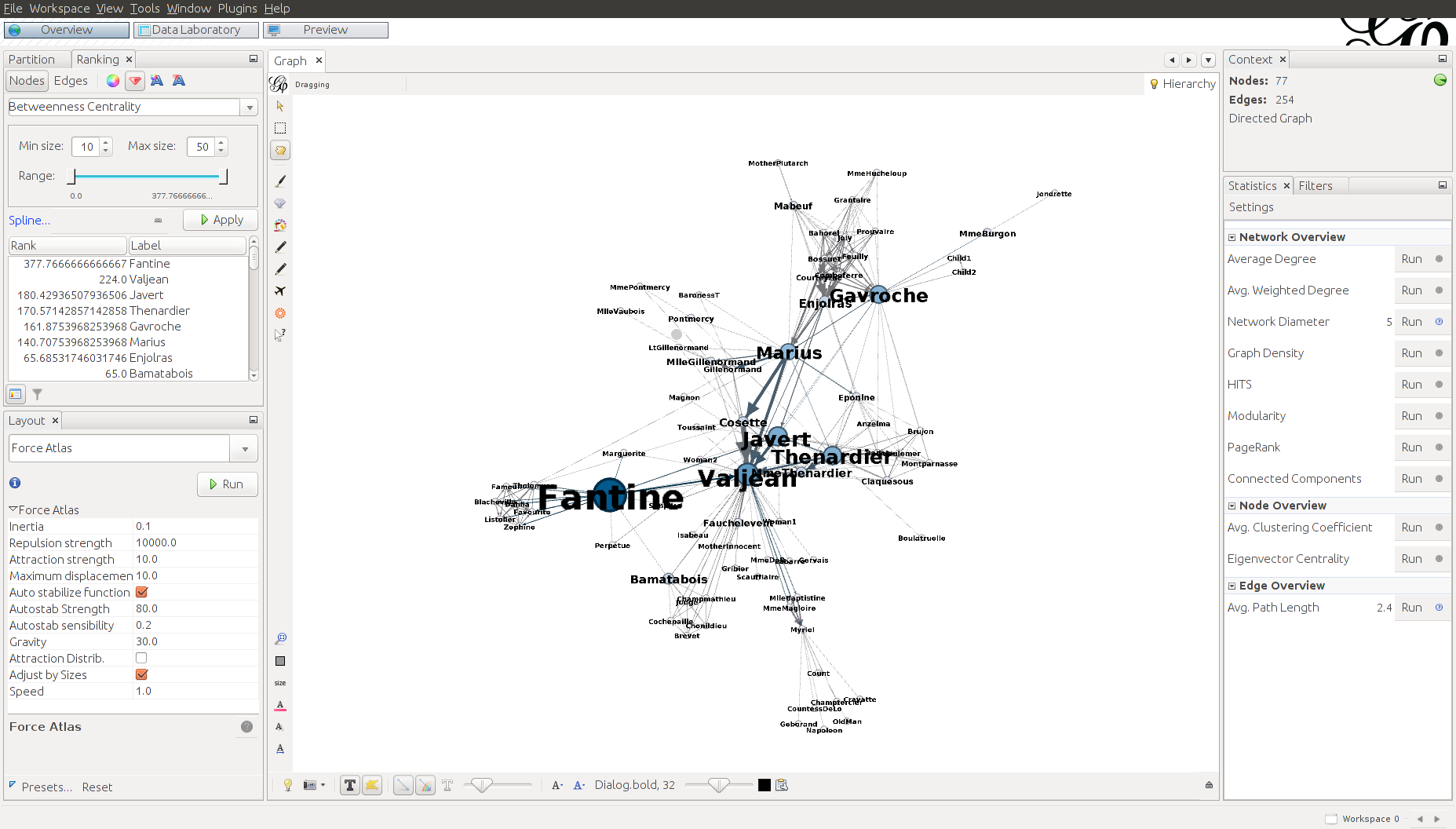
However, just because a character has the most connections doesn’t mean they are the most influential, and an alternative measure, called betweenness centrality, is a measure of a node’s importance. Below, we can see that Fantine has the highest betweenness centrality:

Gephi can also determine the groups to which characters belong, denoted by color:
The dataset that was used to generate these diagrams is in XML format:
And below you can see what the complete GUI looks like:
Well that’s it for today! I’ll look into the software to understand how it works and to see if I can integrate parts of it into my hxgrd project.