I’ve written about spaced repetition a few times in the past, which is a useful method of study aimed at long-term memory retention. I won’t go over the details here, but if you are curious, you can read over these previous posts.
Over the years, it’s become apparent to me that if I am to continue on my path of lifelong learning and retention, I’d have to find a way to preserve my collection of cards permanently.
This has influenced my choice of software – which is to stick with open source tools as much as possible. Software applications can become outdated and discontinued, and sometimes even the vendor can go bankrupt. In this case, you may end up permanently losing data if the application or code that uses it is never made available to the public.
This risk has led me to desire an open source SRS (Spaced Repetition System) that stores data in an accessible, widely-recognized format. Anki meets these two needs quite well, using a SQLite database to store the cards, and LaTeX to encode mathematical notation. Furthermore, the source code is freely available, so should anything happen to Damien Elmes (the creator of Anki), other users can step in to continue the project.
What’s really nice about Anki is the mobility it has offered me when it comes to studying. Not only do I have Anki installed on my home desktop, but I also have it installed on my phone (AnkiDroid), and my personal laptop. Each of these devices can be synced with a service called AnkiWeb, which is a cloud-based platform that syncs the same collection across devices. This allows me to study anywhere – for example, I can study at home before I go to work, sync the collection with my phone, then study on the bus, sync the collection with my laptop, and then study during my lunch break. This allows me to study at times during which I would otherwise be doing nothing (like commuting), boosting my productivity.
AnkiWeb does however, come with its limitations. It’s proprietary, so if the service shuts down or is discontinued for whatever reason, I may be left scrambling for a replacement. Furthermore, it’s also a free service, so collection sizes are limited to 250 MB (if there were a paid option, I’d gladly pay for more), and having to share the service with other users can slow down data transfer at times of peak usage.
These limitations have led me to use an alternative syncing service. For about a year I used David Snopek’s anki-sync-server, a Python-based tool that allows you to use a personal server as if it were Ankiweb:
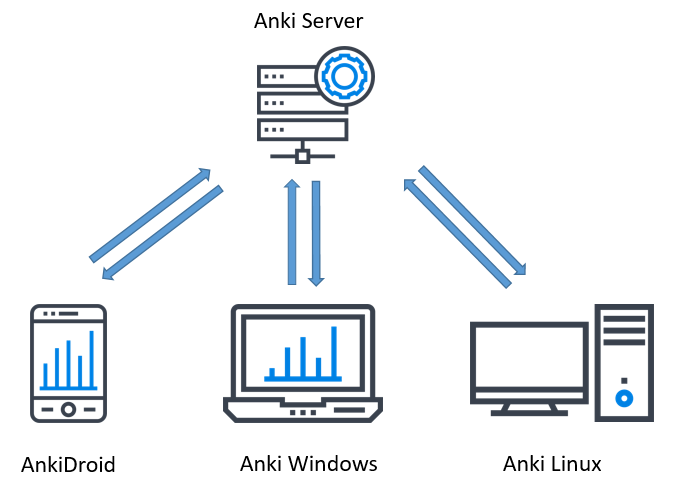
The way it works is that the program is installed on a server (this can be your personal desktop), and a copy of the Anki SQLite database storing your collection is also placed on this server. Then, instead of pointing to AnkiWeb, each device on which Anki is installed points to the server. anki-sync-sever then makes use of the Anki sync protocol to sync all the devices, giving you complete control over how your collection is synced.
Unfortunately, the maintainer of the project stopped updating it two years ago, and to make matters worse, I found out in the middle of last year that Damien Elmes planned to release Anki 2.1, porting the code from Python 2 to Python 3, which meant that anki-sync-server would no longer work once the new version of Anki was released. This led me to search for a workaround, which fortunately I found from another github user, tsudoko, called ankisyncd.
tsudoko forked the original anki-sync-server and ported the code from Python 2 to Python 3. Over the development period and beta testing of Anki 2.1, I would periodically check back with both the ankisynced and Anki repos to test whether the two programs were compatible with each other. This was a very difficult task, since it was very hard to install Anki 2.1 from source – doing so required me to install a large number of dependencies on a very modern development platform. Once Anki 2.1 was released, it took me another two days to figure out how to get my server up and running. Because this was so challenging, I decided to write a guide to help anyone who is interested in setting up their own sync server, as well as a reference for myself.
Setting Up the Virtual Machine
I have ankisynced installed on my regular machine, but it’s easy to experiment (and fail) on a virtual machine, so I advise you to do the same. While I was testing ankisynced and Anki 2.1 beta, I used an Ubuntu 18.04 virtual machine on Virtualbox
Installing the Dependencies
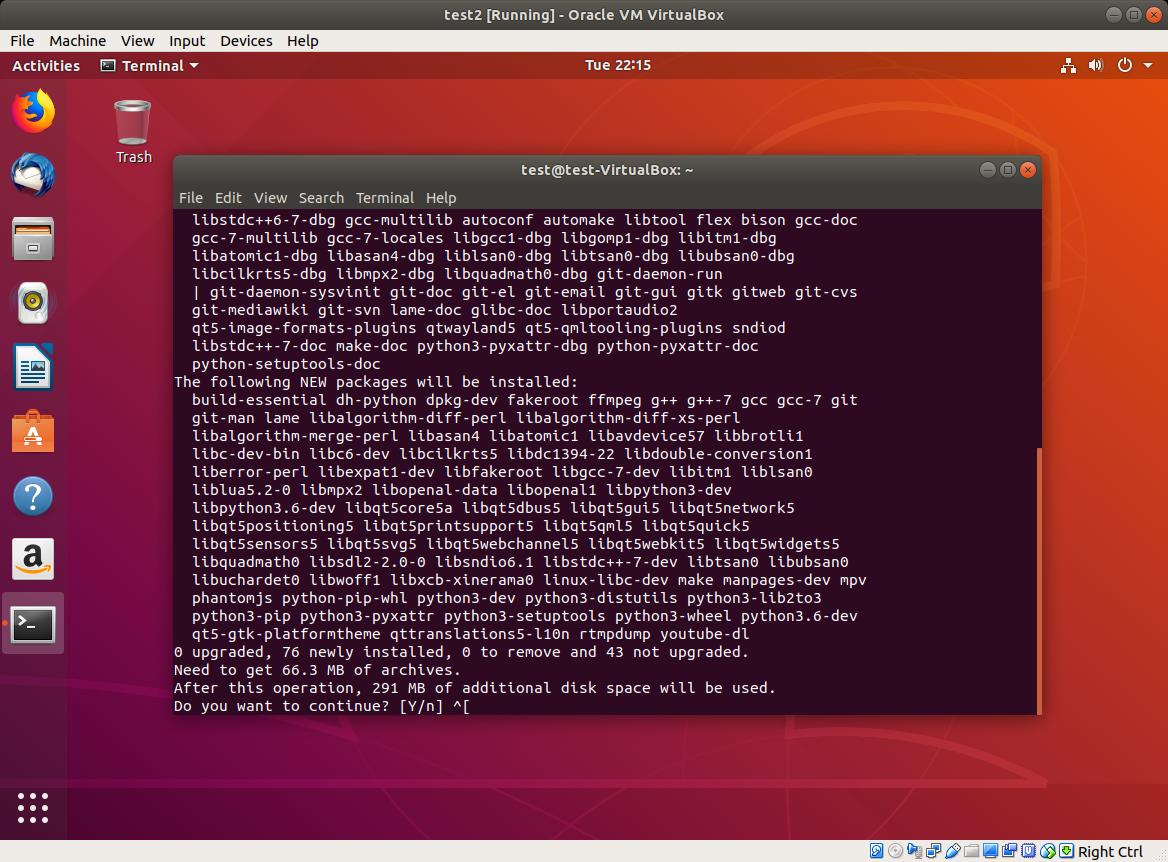
Anki 2.1, although already released, is still somewhat challenging to install from source due to the large number of dependencies. Damien’s developer guide helped me a bit on this front. Once you get your virtual machine launched, open up a terminal and install the following packages:
|
1 2 |
sudo apt-get install python3-pip make git mpv lame sudo pip3 install sip pyqt5==5.9 |
Your window should look like this:
Next, you’ll need to install pyaudio. I had issues trying to do a pip install, so you may need to install portaudio first. The following code downloads and installs portaudio, and then installs pyaudio:
|
1 2 3 4 5 6 7 |
wget http://portaudio.com/archives/pa_stable_v190600_20161030.tgz tar -zxvf pa_stable_v190600_20161030.tgz cd portaudio ./configure && make sudo make install sudo ldconfig sudo pip3 install pyaudio |
Clone the GitHub Repositories
Next, you’ll need to clone both the Anki and ankisyncd repositories. What this means is that you’ll simply download the repos into your home directory:
|
1 2 3 |
cd ~ git clone https://github.com/dae/anki git clone --recursive https://github.com/tsudoko/anki-sync-server |
Install More Dependencies
Anki 2.1 requires more dependencies. Fortunately, some are already listed in the repo, so you can just cd into it and install them from there:
|
1 2 |
cd ~/anki sudo pip3 install -r requirements.txt |
Install Anki
Next, we install from source:
|
1 2 |
sudo ./tools/build_ui.sh sudo make install |
Move Modules Into /usr/local
In order to make use of Anki’s sync protocol, the modules need to be picked up by PYTHONPATH. One way to do that is to copy them into /usr/local. In the following code, replace “test” with your ubuntu username:
|
1 2 |
sudo cp -r /home/test/anki-sync-server/anki-bundled/anki /usr/local/lib/python3.6/dist-packages sudo cp -r /home/test/anki-sync-server/ankisyncd /usr/local/lib/python3.6/dist-packages |
Next, start up Anki, and then close it. You’ll need to do this so that the addons folder is created in your home drive.
Configure ankisyncd
You’ll need to install one more dependency, webob:
|
1 2 |
cd ~/anki-sync-server sudo pip3 install webob |
Next, you’ll need to configure the file. Open up ankisyncd.conf in the text editor:
|
1 |
gedit ankisyncd.conf |
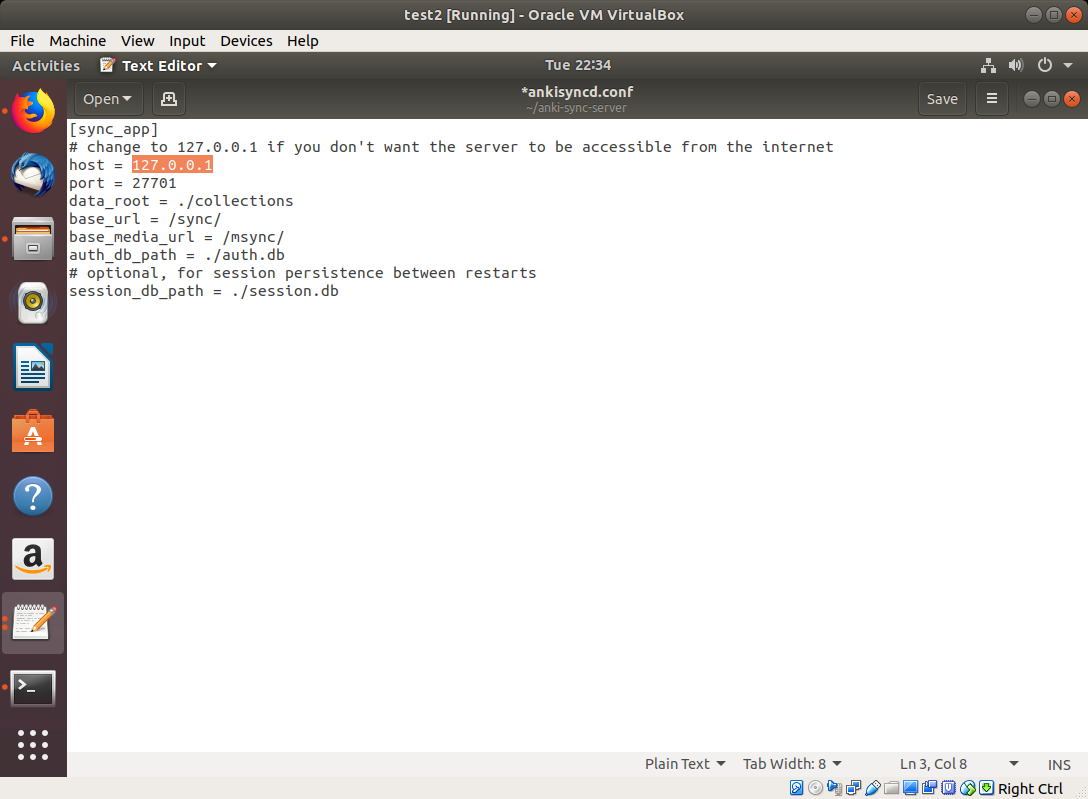
Replace the host IP with the IP address of your server. You’ll see 127.0.0.1 in the image, but you should replace it with its network IP address (this part might be tricky if you haven’t done it before):
|
1 2 3 4 5 6 7 8 9 10 |
[sync_app] # change to 127.0.0.1 if you don't want the server to be accessible from the internet host = 127.0.0.1 port = 27701 data_root = ./collections base_url = /sync/ base_media_url = /msync/ auth_db_path = ./auth.db # optional, for session persistence between restarts session_db_path = ./session.dbr |
Next, you’ll need to create a username and password. This is what you’ll need to use when syncing with Anki. Replace “test” with your username and enter a password when prompted:
|
1 |
sudo python3 ./ankisyncctl.py adduser test |
Now, you’re ready to start ankisyncd:
|
1 |
sudo python3 ./ankisyncd/sync_app.py ankisyncd.conf |
If the above command was successful, you should see the following:
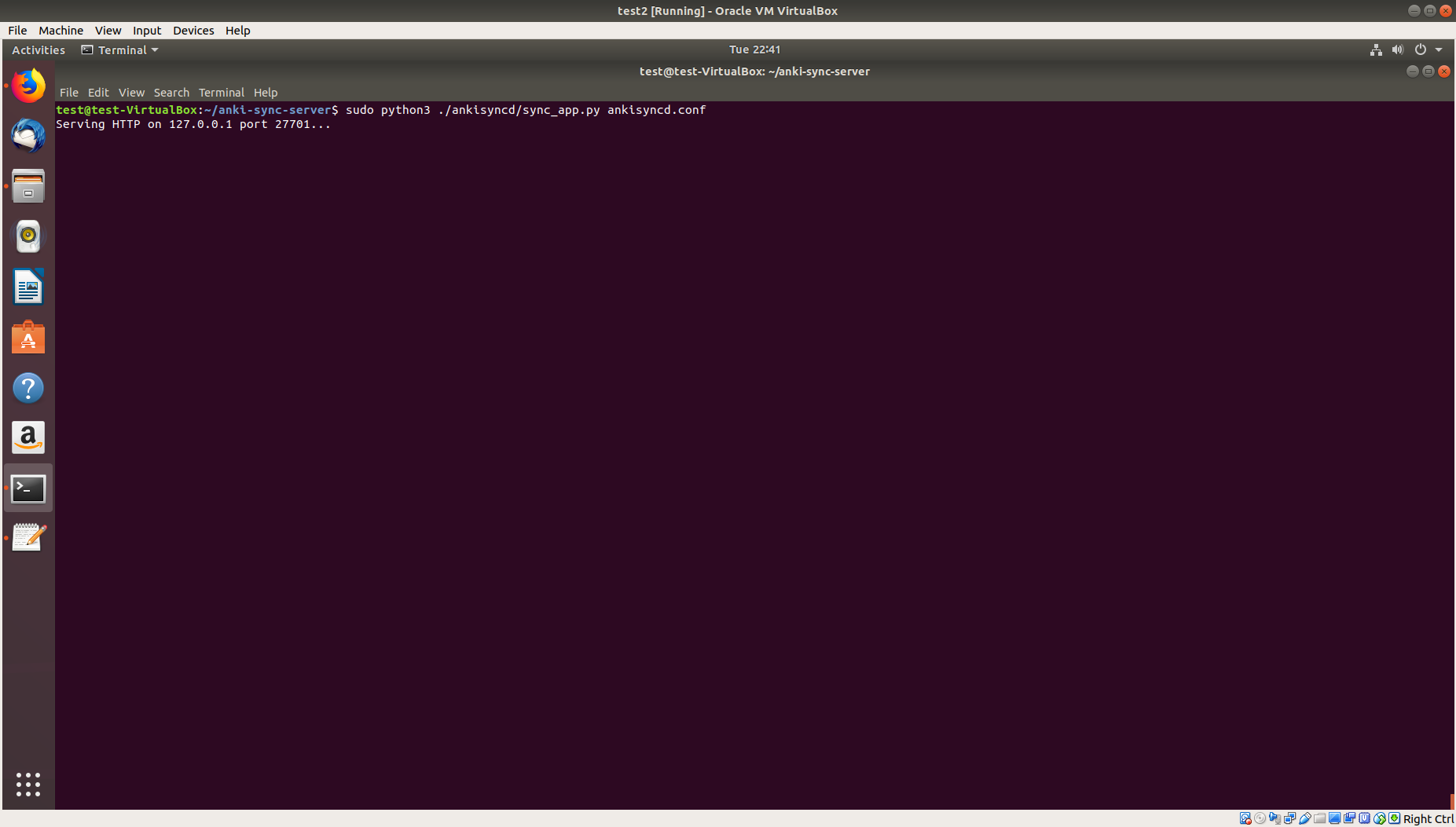
This means that the server is now running.
Install Addons on Client Devices
In order to get ankisyncd syncing with your other devices, you’ll need to configure the addons directory on those devices to get Anki to sync with your server. You can also do this with the host machine (which we’ll try here), but you need to repeat this procedure on all your client devices.
On Ubuntu 18.04, this directory is ./local/share/Anki2/addons21/.
Create a folder called ‘ankisyncd’ and within that folder, create a file called __init__.py:
|
1 2 3 4 |
cd ~/.local/share/Anki2/addons21 mkdir ankisyncd cd ankisyncd touch __init__.py |
On Windows, do the same thing, but in the addons folder for the Windows version of Anki. It will sync, even if the server is running Linux.
Sync
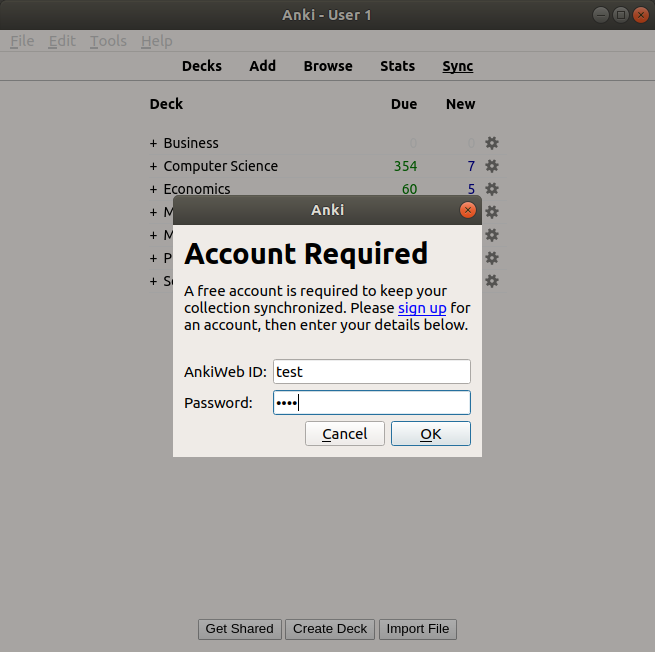
Now, you’re ready to launch Anki. Launch Anki on the host machine or a client device (better to try the host machine first). When you’re ready to sync, click the sync button. A dialogue box will pop up asking for credentials, as if you were logging into AnkiWeb. Enter the credentials that you made during configuration, and the app should sync to your server instead of AnkiWeb.
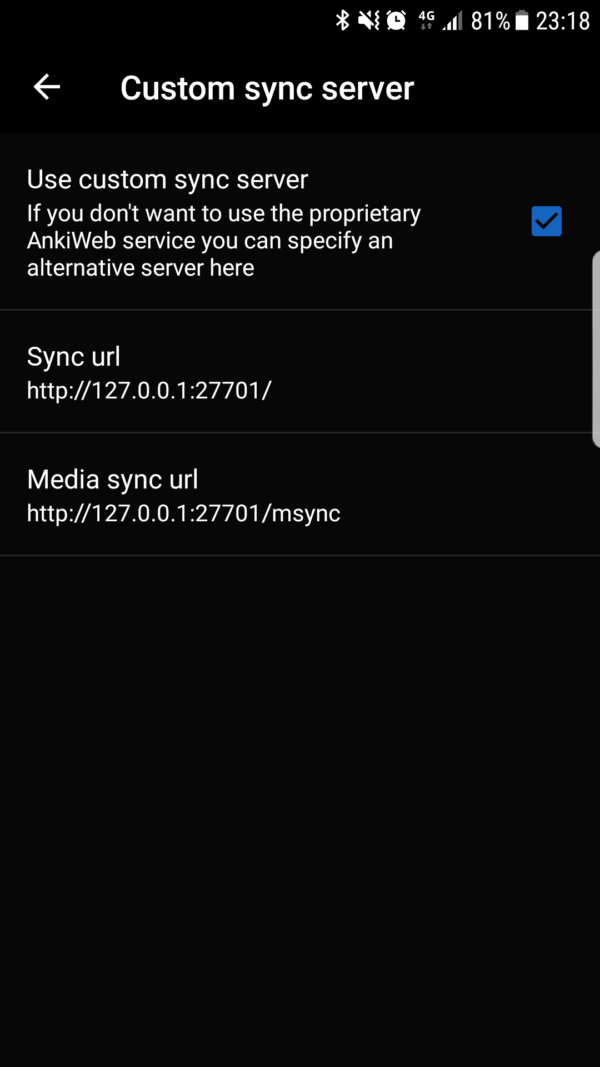
Syncing with AnkiDroid
To sync with AnkiDroid, go to Settings > Advanced > Custom sync server. Check the “Use custom sync server” box. Enter the following parameters for Sync url and Media sync url:
Sync url
http://127.0.0.1:27701/
Media sync url
http://127.0.0.1:27701/msync
But, replace 127.0.0.1 with the public IP of your host machine.
Ending Remarks
As you can see, the setup is not a trivial task, which is the downside of trying to use ankisyncd. Believe it or not, it was even harder with anki-sync-server!. This is just one out of many examples of what open source enthusiasts have to deal with on a daily basis. However, power users and experienced users like myself get complete control over the sync process. Though the process, I did learn a lot about the installation process (installing from source and not just clicking a button), GitHub, and networking.
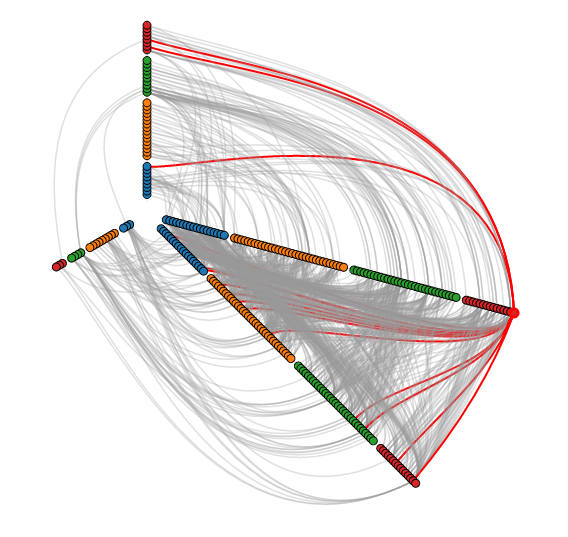 There are various layouts that you can choose from to visualize a network. All of the networks that you have seen so far have been drawn with a force-directed layout. However, one weakness that you may have noticed is that as the number of nodes and edges grows, the appearance of the graph looks more and more like a hairball such that there’s so much clutter that you can’t identify any meaningful patterns.
There are various layouts that you can choose from to visualize a network. All of the networks that you have seen so far have been drawn with a force-directed layout. However, one weakness that you may have noticed is that as the number of nodes and edges grows, the appearance of the graph looks more and more like a hairball such that there’s so much clutter that you can’t identify any meaningful patterns.