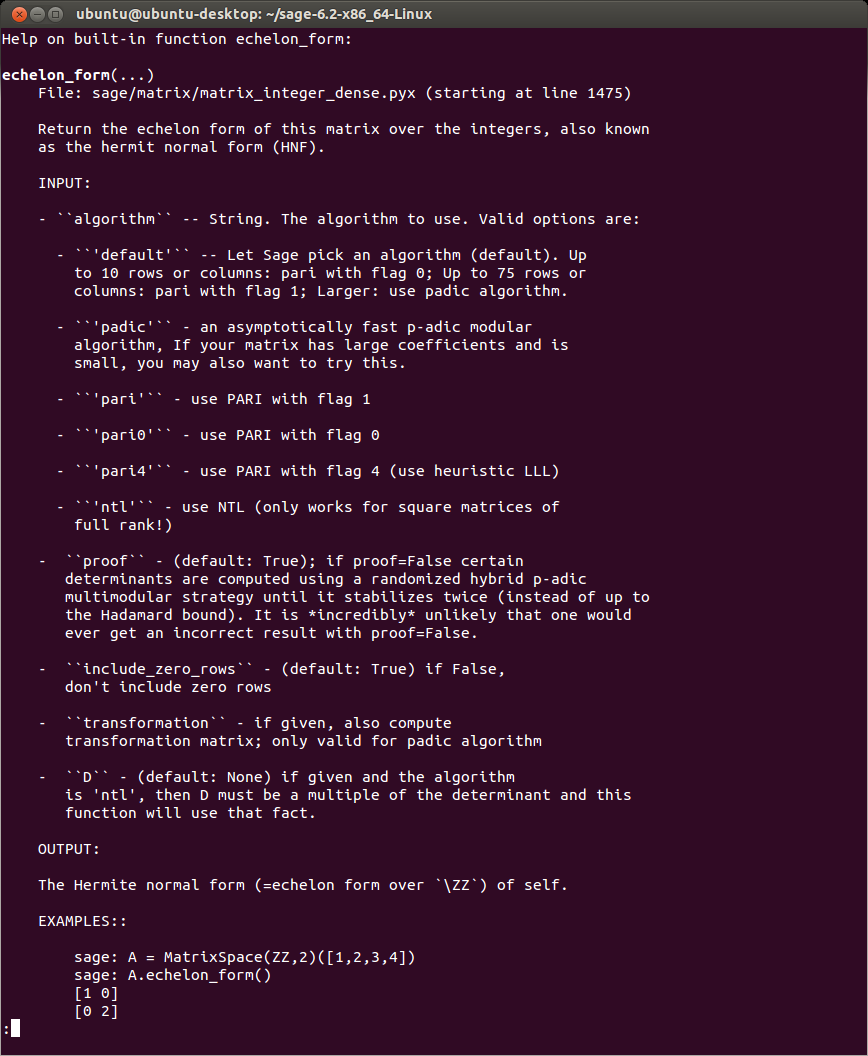
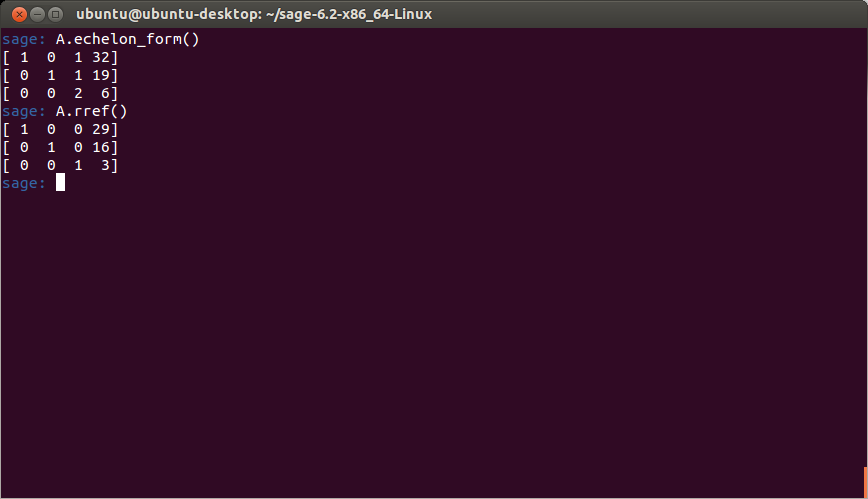
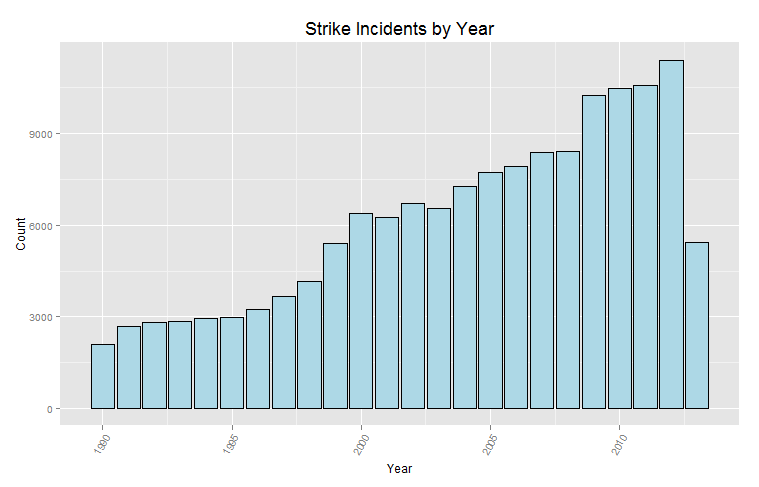
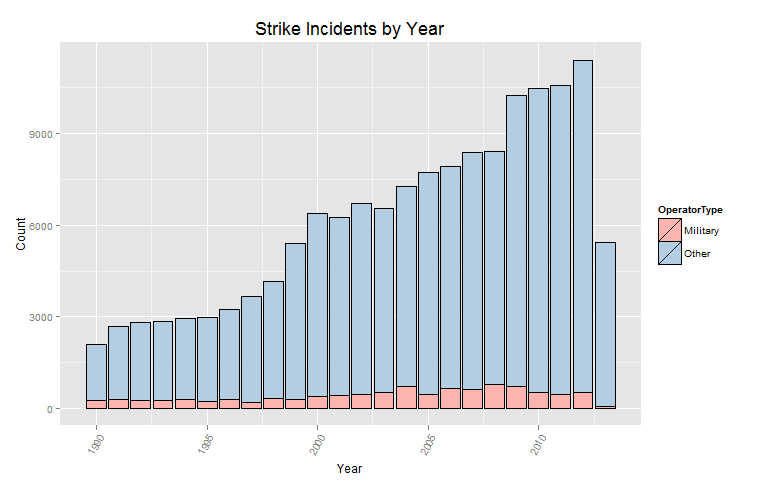
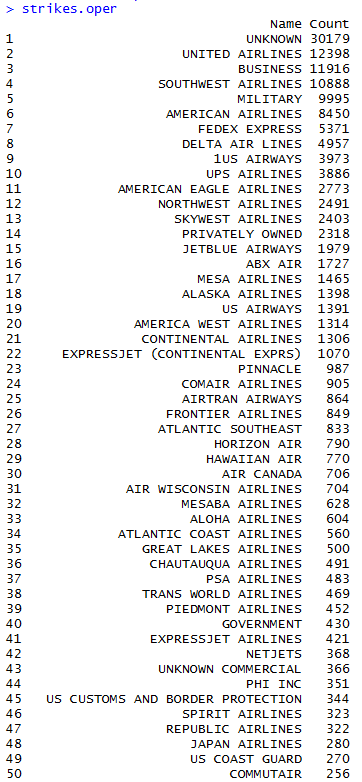
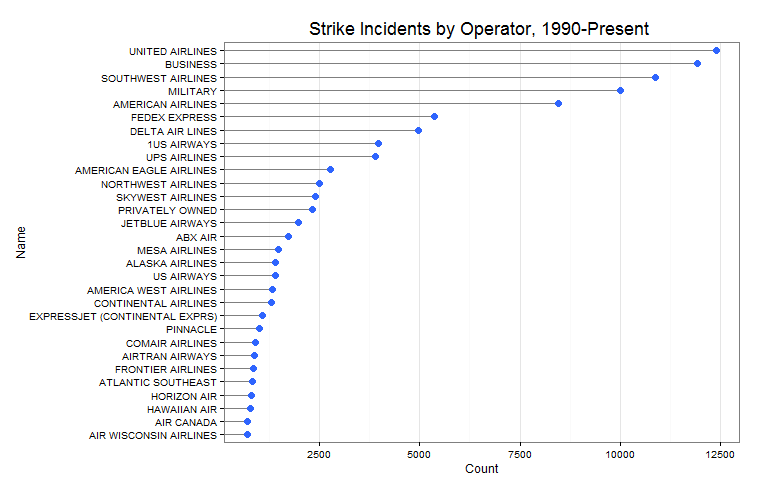
So I want to understand everything. Unfortunately, my limited lifespan, along with the seemingly infinte amount of information there is out there makes this goal impossible. I suppose I should try to understand as much of the universe as possible while making my best effort to contribute to mankind’s body of knowledge.
I’ve been playing around with an open source diagramming tool called Dia, which makes it easy to draw all sorts of visual models from EER diagrams to project management flowcharts. One of the challenges that exists when it comes to discovery is being able to successfuly communicate your findings to a wider audience. You might discover something profound, but if you cannot get anyone else to understand what you have found, or at least be aware of it, what ever you have found will be lost to humanity after your passing.
Fortunately in this day in age, we have the internet. That gives society the capicity to share information at previously unimaginable speeds – and Dia is just one tool out of many that allows people to distill complex ideas into simple diagrams, to be sent to a wide audience via the information superhighway. There are tradeoffs, of course. A diagram cannot capture every single detail about a concept and thus can leave out crucial information. However, the need to quickly reach as many people as possible with a basic concept outweighs the need to cram every single detail possible into a single transmission.
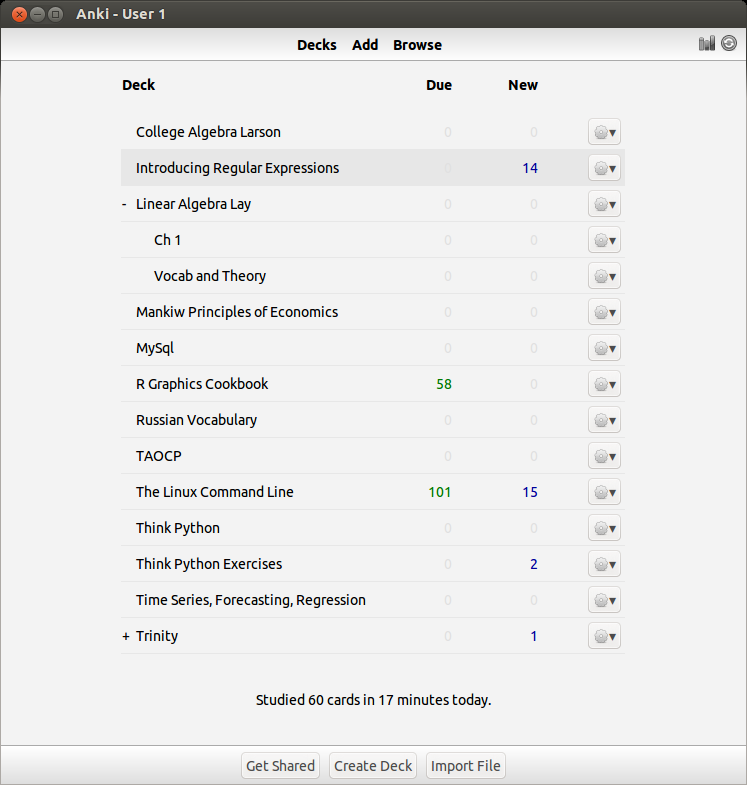
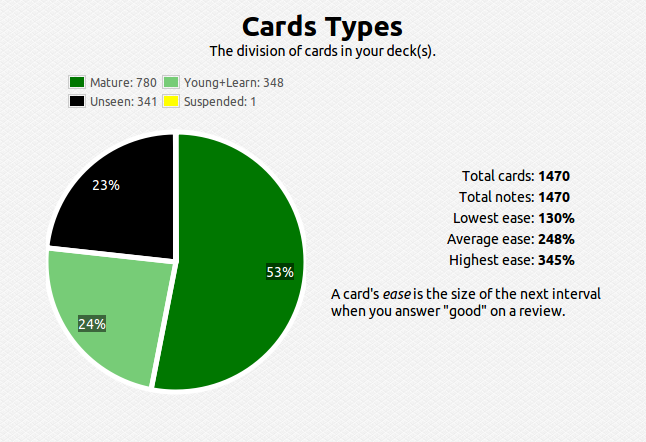
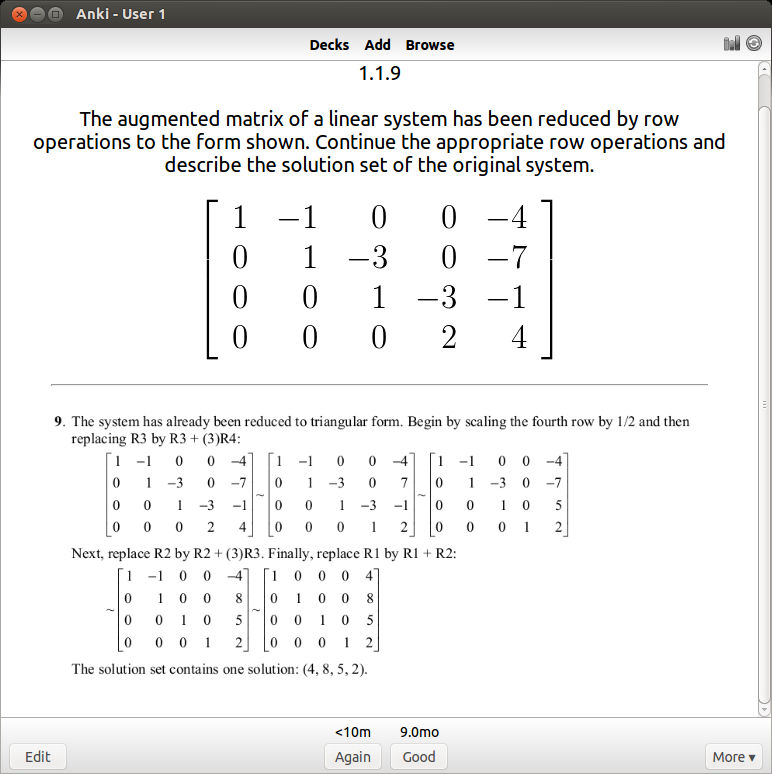
Anyway, I have been using Dia in an attempt to further clarify my educational goals by sketching visual models of the interdependencies of the various subjects that I’ve been studying. I have had an increasing interest in studying the physical world – of the physical sciences, I’ve studied biology the most (3 semesters including genetics), but I never really got around to seriously studying chemistry or physics. So the initial goal for me in this realm (I’ve called it “Trinity”) is to get a firm footing in general bio/chem/phys. Using basic college texts, in combination with spaced repetition techniques, I think I’ll be able to understand and retain enough information to tackle the interdisciplinary subjects of physical chemistry, biochemistry, and biophysics.

However, I’ve found out that you cannot study subjects in isolation, there will always be times where you’ll need to pull information from other fields to tackle a problem. I encountered this issue when studying genetics in college, where a good grasp of combinatorics is needed. Likewise in general chemistry, solving systems of linear equations is required to balance chemical formulas. I majored in math so I have visited quite a few of the subjects below. The diagram is oversimplified, as you cannot realistically expect such a clean linear progression when studying mathematics:

And then there’s Philosphy. I might have taken 6 or 7 philosphy courses in college, unfortunately most of them involved reading excerpts from famous philosophers (Socrates, Plato, Descartes, etc.) and didn’t cover any general philosphy, so I lack the vocabulary to articulate what I’d like to study here. As I look into this subject more deeply I’ll be able to add more things to the diagram:

I majored in economics, the only topics I haven’t visited below are advanced macro/microeconomic theory, which are graduate subjects:

The use of computers as greatly amplified mankind’s ability to synthesize and make use of information. And for individuals, as increased their ability to access and organize information for their own purposes. Computers are immensely useful. They allow people to calculate as well as conduct experiments via simulation that are pratically infeasible in society due to various constrants:

So putting everything together…

In short I like to study systems. I want to know more about power and control, how economies rise and how they collapse, and how biological and social systems remain stable or evolve over time. The closest thing I could find that’s similar to this idea is cybernetics, but I’d have to admit that the wikipeida article is currently over my head, so I could be wrong, and I’d have to update the diagram if that’s the case.
Anyway the diagram isn’t accurate – many of these subjects aren’t concretely defined and there’s a lot of overlap between them. Likewise the order of study and the interdependencies aren’t as neat either, but at the very least, articulating my thoughts is a start and invites feedback. As I proceed, I’ll encounter mistakes and dead ends, and corrections will have to be made, but that’s all part of the learning process.