Introducing MYLIN
MYLIN is the storage system for MIES, an insurance simulation engine I introduced back in November. It is envisioned to consist of a collection of Postgresql databases representing the various firms as well as the attributes of the environment in which they coexist. Although AWS seems to be promoting the use of NoSQL services such as DynamoDB, I have opted not to use them yet as most insurance companies I’ve encountered heavily rely on relational databases, or even IBM mainframes for storing data. Furthermore, SQL ought to be a core skill for actuaries and other analytical professionals for the foreseeable future, so Postgres should be a suitable choice given its rich features, ANSI compliance, and open source development.
MYLIN is named after Maya Lin, the architect. Alternatively, it also refers to myelin, the biological substance that insulates neurons. I suppose it could also be short for My Linh, a common Vietnamese name for females, but I’m not going to promote that interpretation heavily. Otherwise, it doesn’t stand for anything as an acronym.
psycopg2
MIES, as currently envisioned, is primarily written in Python. Since the routines for simulating losses and other events are written in Python, a library is required to access Postgres in order to populate the database tables with the output from these routines. The most popular library is psycopg2, which lets you easily establish a connection to Postgres, create tables, and execute queries against the database.
There are plenty of tutorials out there on how to install and configure Postgres, so I won’t go there. Today I’ll go over the structure of what I’ve got in place for MIES/MYLIN so far, and where I’ll need to go from there. Right now, I have four modules pushed to the GitHub repository:
- connect.py – a script used to establish a connection to Postgres
- config.py – a script that reads in parameters pertaining to my instance of Postgres
- create_tables.py – a script used to create tables for MYLIN
- populate_claims.py – a simple script that generates 10 random claims and writes them to the database
Connecting to Postgres
For now I’ve created a database on my local machine called claimsystem. This all subject to change, especially once I move things onto AWS. But for now, my first goal is to figure out how to establish a connection to Postgres and execute queries via Python. I’ve adapted some code from a tutorial I read. For the most part, it’s not much different, except I’ve imported the os module to refer to my configuration file via a relative path which points outside the repository, since I don’t want to upload it to GitHub (alternatively, I could put the file in .gitignore). I feel uncomfortable leaving a password in a plain text file, so I’m actively looking for a more secure way to handle the connection (suggestions welcome):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
#!/usr/bin/python import psycopg2 import os from config import config #keep the config file out of the repository until I figure out a more secure way to handle this ini_path = os.path.abspath(os.path.join(__file__,"../../..","database.ini")) def connect(): """ Connect to the PostgreSQL database server """ conn = None try: # read connection parameters params = config(ini_path) # connect to the PostgreSQL server print('Connecting to the PostgreSQL database...') conn = psycopg2.connect(**params) # create a cursor cur = conn.cursor() # execute a statement print('PostgreSQL database version:') cur.execute('SELECT version()') # display the PostgreSQL database server version db_version = cur.fetchone() print(db_version) # close the communication with the PostgreSQL cur.close() except (Exception, psycopg2.DatabaseError) as error: print(error) finally: if conn is not None: conn.close() print('Database connection closed.') |
Referencing the code above, I’ve also imported a module called config, which is the script that reads in the database connection parameters:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#!/usr/bin/python from configparser import ConfigParser def config(filename, section='postgresql'): # create a parser parser = ConfigParser() # read config file parser.read(filename) # get section, default to postgresql db = {} if parser.has_section(section): params = parser.items(section) for param in params: db[param[0]] = param[1] else: raise Exception('Section {0} not found in the {1} file'.format(section, filename)) return db |
Creating Tables
The next step is to create some tables in the database. Since I’d like to just test out psycopg2’s ability to connect and execute queries, it’s best to keep things simple for now, test the connection, and then increase the complexity from there. For now, I’ve created one table called Claim with two fields, claim_id – to identify each claim, and loss_amount – the corresponding loss amount. This table will hold 10 randomly generated claims along with their corresponding identifiers and loss amounts.
To create the table, I’ll need to send the following query to Postgres:
|
1 2 3 4 |
CREATE TABLE Claim ( claim_id SERIAL PRIMARY KEY, loss_amount NUMERIC NOT NULL ) |
Since claim_id is of type SERIAL, it’s automatically generated each time a new record is created. This means I only have to worry about the loss amount (for now). The next step is to embed this query into a Python script, using psycopg2 to connect and send the query to the database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import psycopg2 import os from config import config #keep the config file out of the repository until I figure out a more secure way to handle this ini_path = os.path.abspath(os.path.join(__file__,"../../..","database.ini")) def create_tables(): """ create tables in the PostgreSQL database""" commands = ( """ CREATE TABLE Claim ( claim_id SERIAL PRIMARY KEY, loss_amount NUMERIC NOT NULL ) """, ) conn = None try: # read the connection parameters params = config(ini_path) # connect to the PostgreSQL server conn = psycopg2.connect(**params) cur = conn.cursor() # create table one by one for command in commands: cur.execute(command) # close communication with the PostgreSQL database server cur.close() # commit the changes conn.commit() except (Exception, psycopg2.DatabaseError) as error: print(error) finally: if conn is not None: conn.close() if __name__ == '__main__': create_tables() |
Generating Claims
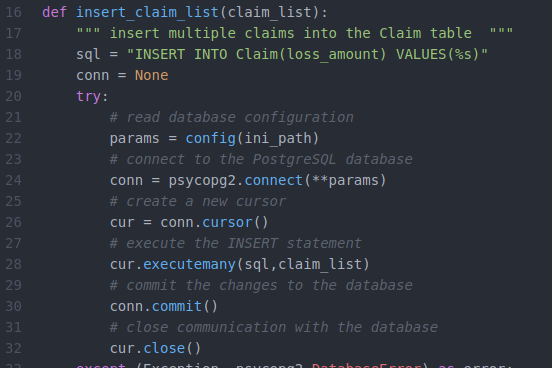
Now, I’d like to see whether I can insert some records to the table I just created. In this example, I’ll generate 10 random claims to be inserted. To do so, I’ve imported the random library from Python to assign a random number to each claim as a loss amount. I’ll worry about making things more mathy and realistic later on, but for now I just need to get the basics right:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
#!/usr/bin/python import psycopg2 import random import os from config import config #keep the config file out of the repository until I figure out a more secure way to handle this ini_path = os.path.abspath(os.path.join(__file__,"../../..","database.ini")) #Generate random claims to be inserted into the Claim table simple_claims = random.sample(range(1000,10000), 10) simple_claims = [(x,) for x in simple_claims] print(simple_claims) def insert_claim_list(claim_list): """ insert multiple claims into the Claim table """ sql = "INSERT INTO Claim(loss_amount) VALUES(%s)" conn = None try: # read database configuration params = config(ini_path) # connect to the PostgreSQL database conn = psycopg2.connect(**params) # create a new cursor cur = conn.cursor() # execute the INSERT statement cur.executemany(sql,claim_list) # commit the changes to the database conn.commit() # close communication with the database cur.close() except (Exception, psycopg2.DatabaseError) as error: print(error) finally: if conn is not None: conn.close() if __name__ == '__main__': # insert multiple claims insert_claim_list(simple_claims) |
This seems to have been successful, since if I query the table directly using psql, I can see the results:
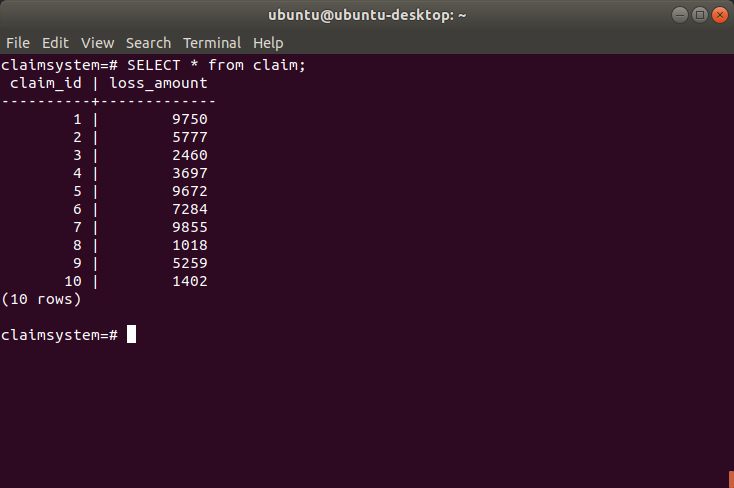
We’ve just got one table with 10 claims and not much else, so one of the next things I want to cover is building a more complete database to represent a data warehouse of an insurance company. I’ll cover this using a pretty neat tool called pgmodeler next week.