Around this time last year, I was frantically studying for my last actuarial exam. With the future of my career on the line, I decided that in the three to four months leading up to my exam, I would drop everything – that is, exercise, hobbies, social activities, and academic interests – to study for this exam. This was an unprecedented move on my end, as I had, up to that point in my career, maintained my outside interests while simultaneously preparing for my exams. However, I believed that since this was my last exam, and with no fall exam on the horizon, that I would be able to catch up on these things later.
The good news is that I passed, after having put in about 6 hours of study per day over the course of 100 days. The bad news is that I had put the rest of my life on hold, including my (hopefully) lifelong experiment with spaced repetition, using Anki. For those of you who are new to this, spaced repetition is an optimized technique for memory retention – you can read more about it here. Halting progress on notecard reviews is problematic, for a couple of reasons:
- There is no way to pause Anki. Anki will keep scheduling cards even when you aren’t reviewing them, so it can be very difficult to catch up on your reviews, even if you’ve missed just a few days.
- Anki schedules cards shortly before you’re about to forget them, which is the best time to review the cards for maximum retention. Because of this, you are likely to forget many of the cards that are on backlog.
Thus, despite the relief I felt over never having to take an actuarial exam ever again, I faced the daunting task of getting back to normal with my Anki reviews. Since I use Anki as a permanent memory bank of sorts, I never delete any of the cards I add – that means I cumulatively review everything I have ever added to my deck over the last five years. This makes the issues I outlined above particularly problematic.
Upon waking up the day after my exam, I discovered that I had over 12,000 cards to review, a backlog which had accumulated over the past three months:
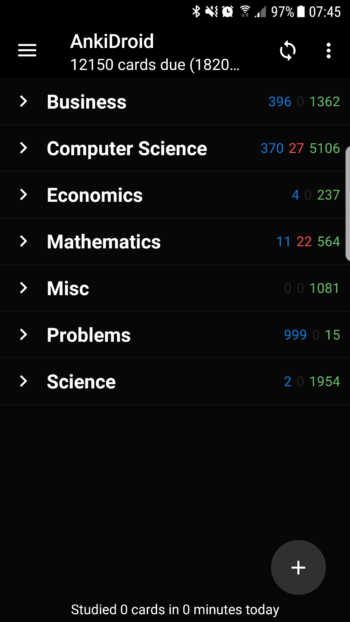
Although I was eager to resume my studies, this backlog would be something I would have to deal with first, since it would be difficult for me to review new material without taking care of the old material first. I assume that most people would simply nuke their collection and start over, but since I had been using Anki for several years, I was confident I’d be able to get through this without having to delete any of my cards.
The first step was to pick the number of reviews I would have to do per day. The tricky part was that if I did too few, the backlog would continue to grow. However, there was no way for me to get through all 12,000 cards within a single day. I settled on starting with 500 reviews per day – a nice, round number that I could easily increase if I noticed I was falling behind.
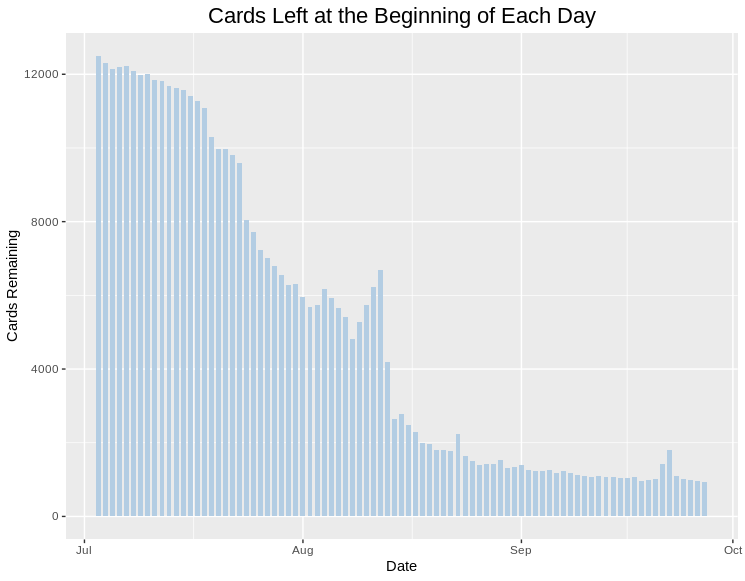
As the days went by, I recorded the number of reviews I had remaining at the start of each day in a file called cardsleft.csv. The graph below shows that it took about three months to reach a level of about 1,000 cards per day, which was the point at which I declared the backlog to be cleared:
|
1 2 3 4 5 6 7 8 |
library(tidyverse) library(RSQLite) library(rjson) library(sqldf) library(treemap) library(anytime) library(zoo) library(reshape2) |
|
1 2 3 4 5 6 7 8 9 10 |
cardsleft <- read.csv("cardsleft.csv", header=TRUE) cardsleft$date <- as.Date(cardsleft$date, "%m/%d/%y") ggplot(cardsleft, aes(x = date, y = cardsleft)) + geom_bar(stat="identity", width = 0.7, fill = "#B3CDE3") + ggtitle("Cards Left at the Beginning of Each Day") + xlab("Date") + ylab("Cards Remaining") + theme(plot.title=element_text(size=rel(1.5),vjust=.9,hjust=.5)) + guides(fill = guide_legend(reverse = TRUE)) |
I worked my way through my collection one deck at a time, starting with programming languages, since I wanted to start studying a new JavaScript book as soon as possible. Once that deck was cleared, I started adding new cards pertaining to JavaScript, while simultaneously clearing the backlog in the remaining decks.
That’s all I had to do, and all it took was a bit of consistency and perseverance over three months. Now things are back to normal – I normally review 800 – 1200 cards per day.
Other Spaced Repetition Updates
It’s been a little more than a year since I last wrote about spaced repetition. I’m happy to say that my experiment is still going strong, and my personal goal of never deleting any cards has not placed an undue burden on my livelihood or on my ability to study new material. Since Anki stores its information in a SQLite database, you can directly connect to it with R to analyze its contents.
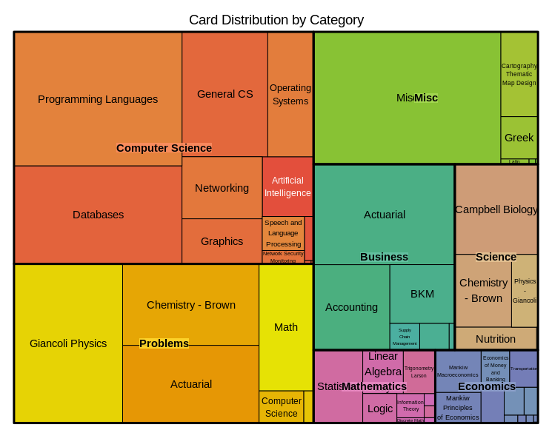
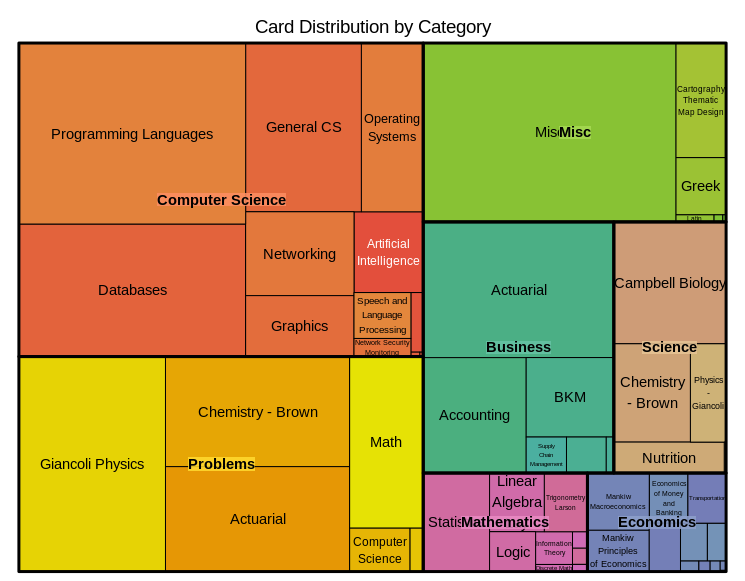
For the most part, the deck composition by subject has remained similar, but the computer science portion has increased due to my focus on databases, JavaScript, Git, and R:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
con = dbConnect(SQLite(), dbname = "collection.anki2") con = dbConnect(RSQLite::SQLite(),dbname="collection.anki2") #get reviews rev <- dbGetQuery(con,'select CAST(id as TEXT) as id , CAST(cid as TEXT) as cid , time from revlog') cards <- dbGetQuery(con,'select CAST(id as TEXT) as cid, CAST(did as TEXT) as did from cards') #Get deck info - from the decks field in the col table deckinfo <- as.character(dbGetQuery(con,'select decks from col')) decks <- fromJSON(deckinfo) names <- c() did <- names(decks) for(i in 1:length(did)) { names[i] <- decks[[did[i]]]$name } decks <- data.frame(cbind(did,names)) decks$names <- as.character(decks$names) decks$actuarial <- ifelse(regexpr('[Aa]ctuar',decks$names) > 0,1,0) decks$category <- gsub(":.*$","",decks$names) decks$subcategory <- sub("::","/",decks$names) decks$subcategory <- sub(".*/","",decks$subcategory) decks$subcategory <- gsub(":.*$","",decks$subcategory) cards_w_decks <- merge(cards,decks,by="did") deck_summary <- sqldf("SELECT category, subcategory, count(*) as n_cards from cards_w_decks group by category, subcategory") treemap(deck_summary, index=c("category","subcategory"), vSize="n_cards", type="index", palette = "Set2", title="Card Distribution by Category") |
In the time that has passed, my deck as grown from about 40,000 cards to 50,000 cards:
|
1 2 3 4 5 6 7 8 9 10 |
cards$created_date <- as.yearmon(anydate(as.numeric(cards$cid)/1000)) cards_summary <- sqldf("select created_date, count(*) as n_cards from cards group by created_date order by created_date") cards_summary$deck_size <- cumsum(cards_summary$n_cards) ggplot(cards_summary,aes(x=created_date,y=deck_size))+geom_bar(stat="identity",fill="#B3CDE3")+ ggtitle("Cumulative Deck Size") + xlab("Year") + ylab("Number of Cards") + theme(plot.title=element_text(size=rel(1.5),vjust=.9,hjust=.5)) + guides(fill = guide_legend(reverse = TRUE)) |
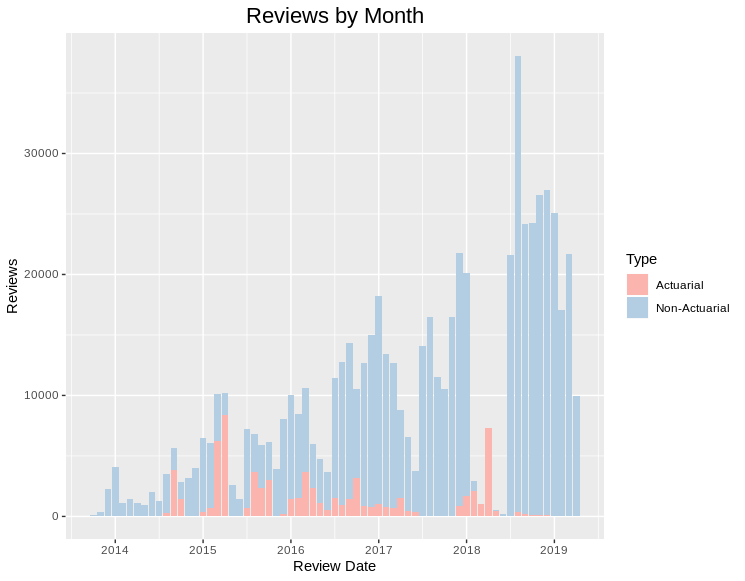
And, thankfully, the proportion of my time preparing for actuarial exams has dropped to near zero:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
#Date is UNIX timestamp in milliseconds, divide by 1000 to get seconds rev$revdate <- as.yearmon(anydate(as.numeric(rev$id)/1000)) #Assign deck info to reviews rev_w_decks <- merge(rev,cards_w_decks,by="cid") rev_summary <- sqldf("select revdate,sum(case when actuarial = 0 then 1 else 0 end) as non_actuarial,sum(actuarial) as actuarial from rev_w_decks group by revdate") rev_counts <- melt(rev_summary, id.vars="revdate") names(rev_counts) <- c("revdate","Type","Reviews") rev_counts$Type <- ifelse(rev_counts$Type=="non_actuarial","Non-Actuarial","Actuarial") rev_counts <- rev_counts[order(rev(rev_counts$Type)),] rev_counts$Type <- as.factor(rev_counts$Type) rev_counts$Type <- relevel(rev_counts$Type, 'Non-Actuarial') ggplot(rev_counts,aes(x=revdate,y=Reviews,fill=Type))+geom_bar(stat="identity")+ scale_fill_brewer(palette="Pastel1",direction=-1)+ ggtitle("Reviews by Month") + xlab("Review Date") + scale_x_continuous(breaks = pretty(rev_counts$revdate, n = 6)) + theme(plot.title=element_text(size=rel(1.5),vjust=.9,hjust=.5)) + guides(fill = guide_legend(reverse = TRUE)) |
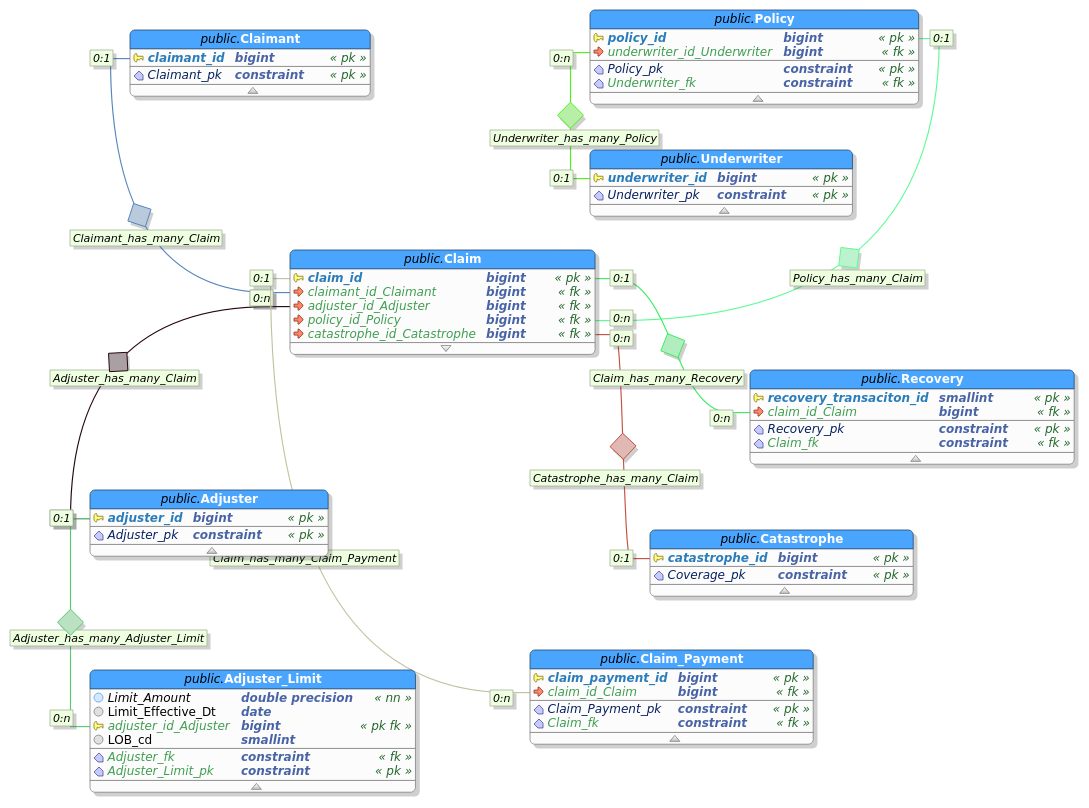 MIES, standing for Miniature Insurance Economic Simulator, is a side project of mine that was originally conceived in 2013. The goal of MIES is to create a realistic, but simplified representation of an insurance company ERP, populate it with simulated data, and from there use it to test economic and actuarial theories found in academic literature. From this template, multiple firms can then be created, which can then be used to test inter-firm competition, the effects of which will be manifested via the simulated population of insureds.
MIES, standing for Miniature Insurance Economic Simulator, is a side project of mine that was originally conceived in 2013. The goal of MIES is to create a realistic, but simplified representation of an insurance company ERP, populate it with simulated data, and from there use it to test economic and actuarial theories found in academic literature. From this template, multiple firms can then be created, which can then be used to test inter-firm competition, the effects of which will be manifested via the simulated population of insureds.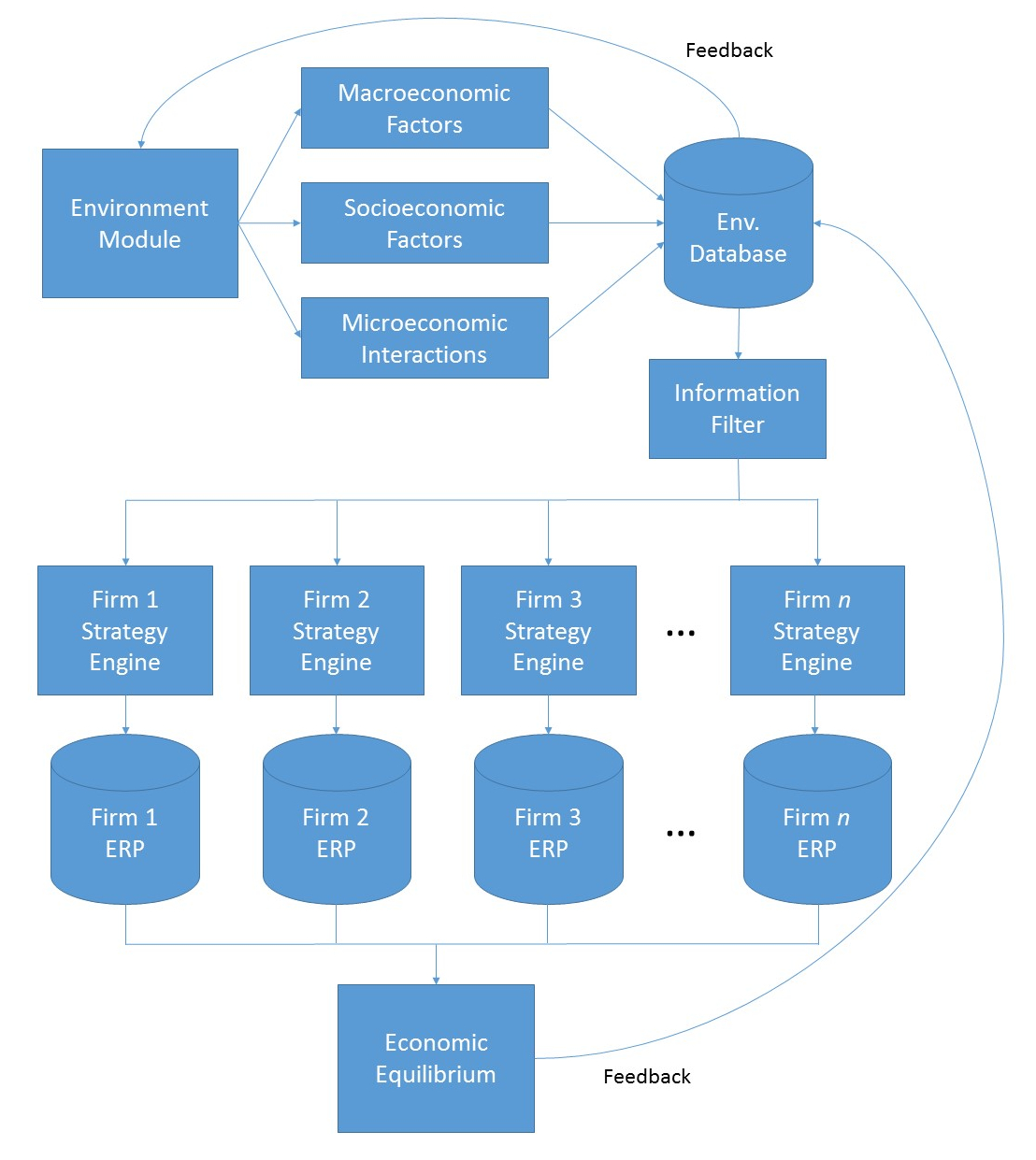
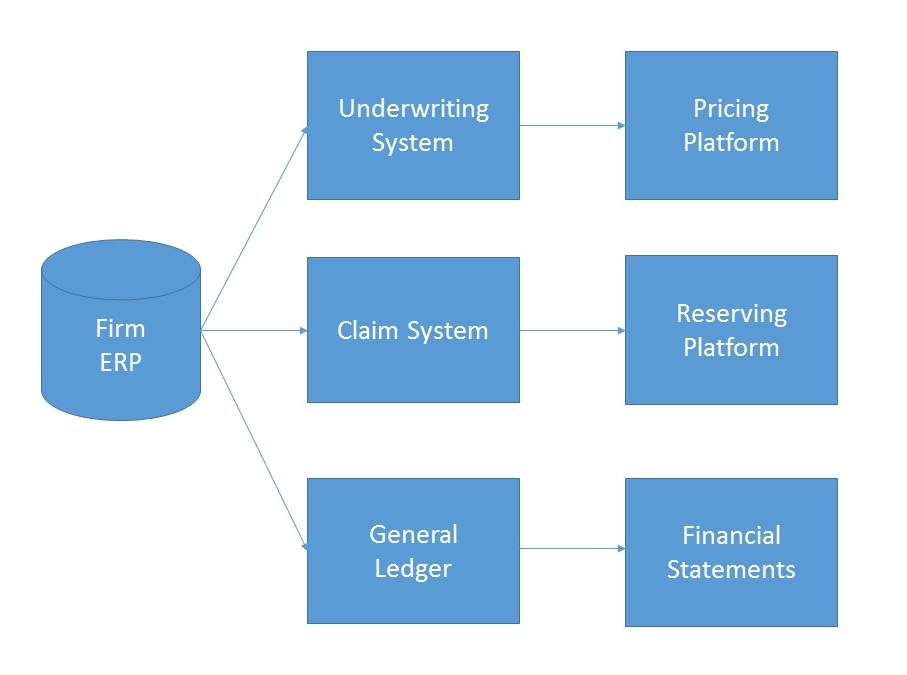
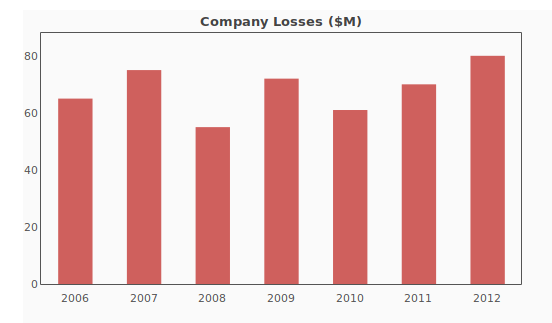
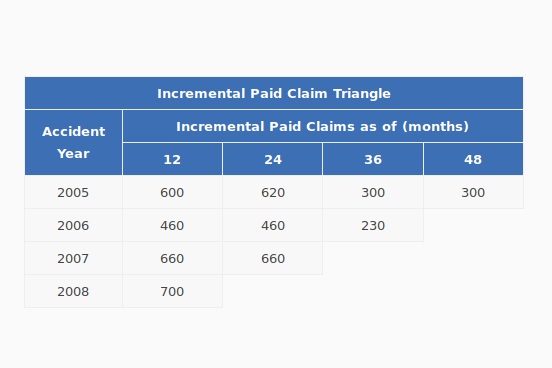 A triangle is a data structure commonly used by actuaries to estimate reserves for insurance companies. Without going into too much detail, a reserve is money that an insurance company sets aside to pay claims on a book of policies. The reason why reserves must be estimated is due to the uncertain nature of the business – that is, for every policy sold, it is unknown at the time of sale whether or not the insured will suffer a claim over the policy period, nor is it known with certainty how many claims the insured will file, or how much the company will have to pay in order to settle those claims. Yet, the insurance company still needs to have funds available to satisfy its contractual obligations – hence, the need for actuaries.
A triangle is a data structure commonly used by actuaries to estimate reserves for insurance companies. Without going into too much detail, a reserve is money that an insurance company sets aside to pay claims on a book of policies. The reason why reserves must be estimated is due to the uncertain nature of the business – that is, for every policy sold, it is unknown at the time of sale whether or not the insured will suffer a claim over the policy period, nor is it known with certainty how many claims the insured will file, or how much the company will have to pay in order to settle those claims. Yet, the insurance company still needs to have funds available to satisfy its contractual obligations – hence, the need for actuaries.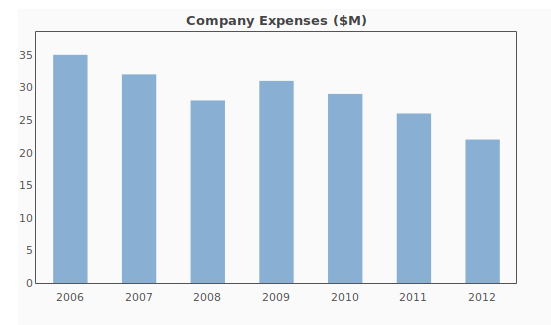
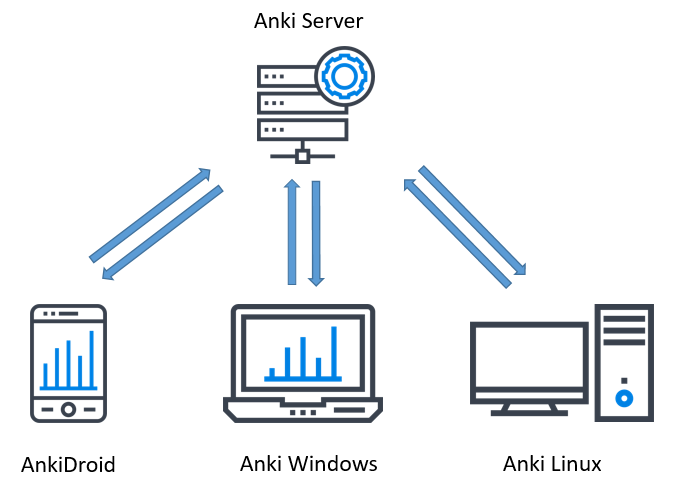
 I’ve got a few side projects going on, one of which involves creating a web application for some of the actuarial libraries I’m developing. Since I have a bad habit of quitting projects shortly after I’ve announced them to the public, I’m going to wait until I’ve made some progress on it. In the meantime, I’d like to talk about some of the tools that I’ve had to learn in order to get this done – one of which is JavaScript.
I’ve got a few side projects going on, one of which involves creating a web application for some of the actuarial libraries I’m developing. Since I have a bad habit of quitting projects shortly after I’ve announced them to the public, I’m going to wait until I’ve made some progress on it. In the meantime, I’d like to talk about some of the tools that I’ve had to learn in order to get this done – one of which is JavaScript.