A few months ago, I introduced MIES, an insurance simulation engine. Although I wanted to work on this for the last few years, I had been sidetracked with exams, and more recently, a research project for the Society of Actuaries (SOA) that involved co-authoring a predictive modeling paper with other actuaries and data scientists at Milliman. That effort took an entire year from the initial proposal to its final publication, of which the copy-edit stage is still ongoing. Once it has been published, I’ll provide another update on my thoughts over the whole process.
Meanwhile, I’ve had some time to get back to MIES. As far as technology goes, a lot has changed over the years, including the introduction of serverless computing – implemented in AWS Lambda in 2014. In short, serverless computing is a cloud service that allows you to execute code without having to provision or configure servers or virtual machines. Furthermore, you only need to pay for what you execute, and there is no need to terminate clusters or machines in order to save on costs. Ideally, this should be more cost (and time) effective than other development options that involve allocating hardware.
Since MIES is cloud-based, I thought going serverless would be worth a try, and was further motivated to do so upon the recommendation of a friend. The following image comes from one of the AWS tutorials on serverless web apps. What I have envisioned is similar, with the exception of using Postgres instead of DynamoDB.
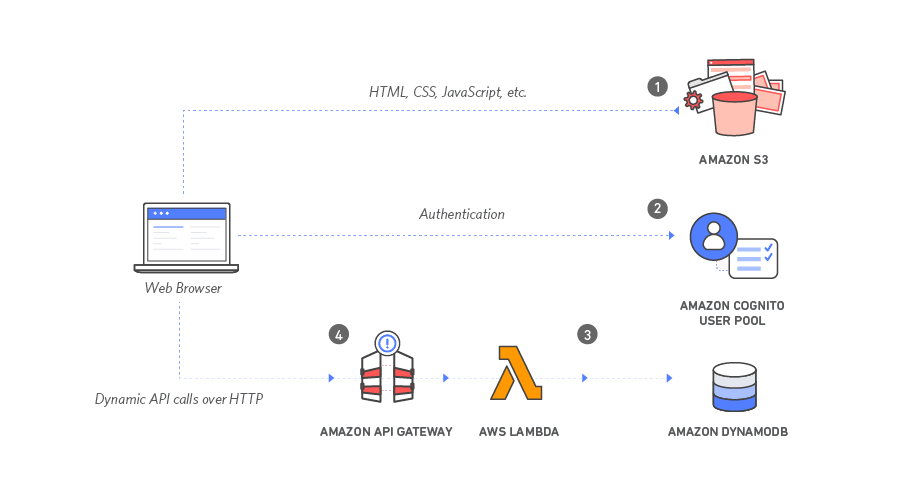
Following the tutorial was easy enough, and took about two hours to complete. My overall assessment is that although I was able to get the web app up and running quickly, many of the pieces of the tutorial, such as the files used to construct the web page, and the configuration options for the various AWS services involved (S3, Cognito, DynamoDB, Lambda, API Gateway) were preset without explanation, which made it hard to really understand how the architecture worked, or what all the configuration options did, or why they were necessary. Furthermore, I think a developer would need to have more experience in the component AWS services to be able to build their own application from scratch. Nevertheless, I was impressed enough to want to continue experimenting with serverless architectures for MIES, so I purchased two books to get better at both AWS itself and AWS Lambda:
One downside to this approach is that while informative, these types of books tend to go out of date quickly – especially in the case of cloud technologies. For example, I have read some books on Spark that became obsolete less than a year after publication. On the other hand, books offer a structured approach to learning that can be more organized and approachable than reading the online documentation or going to Stack Overflow for every problem that I encounter. This is however, cutting edge technology, and no one approach will cover everything I’ll need to learn. I’ll have to take information wherever I can get it, and active involvement in the community is a must when trying to learn these things.
Going back to the original MIES diagram, we can see that serverless computing is ideal:
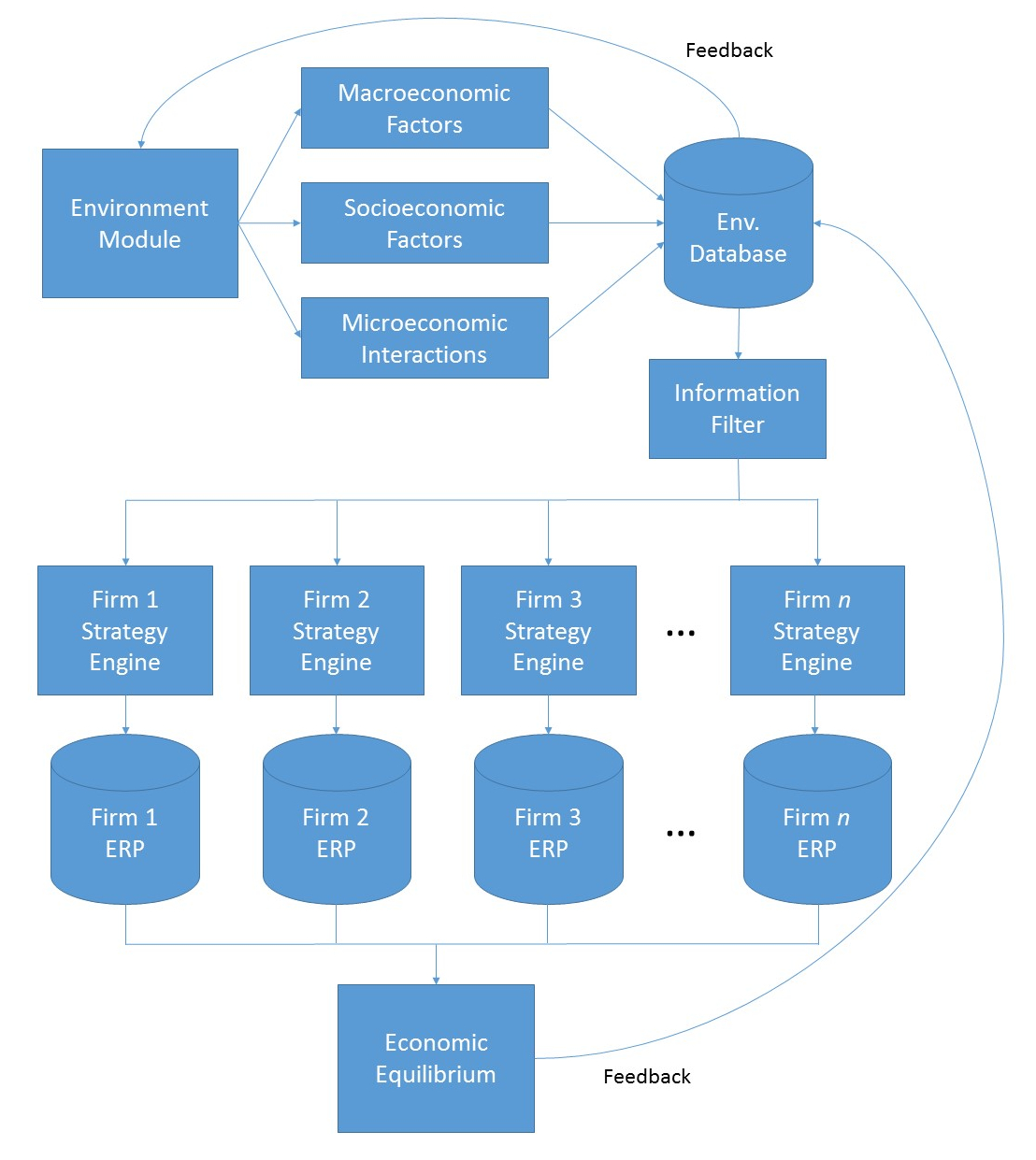
I ought to be able to program the modules in AWS Lambda and store the data in Postgres instances. Having multiple firms will complicate things, as will focusing on the final display of information, along with the user interface. For now, I’ll focus on generating losses for one firm, and then reaching an equilibrium with 2 firms. I already have a schema mocked up in Postgres, and will work on connecting to it with Python over the course of the week.