This entry is part of a series dedicated to MIES – a miniature insurance economic simulator. The source code for the project is available on GitHub.
Current Status
When programming MIES, I face a trade-off between rolling out enough features for a weekly blog post and spending more time trying to learn Python in order to code them in the most elegant way possible. If I implement things too quickly, I face the problem of accumulating bugs and technical debt, but if I spend too much time trying learn the latest libraries, I’d never get anything done. Therefore, I’ve decided to just write what I can most weeks, but revisiting the code to make it better every 3rd or 4th week, so I can implement any new technical knowledge I’d gained during that time.
Last month, I demonstrated the phenomenon of adverse selection using MIES. However, the underlying database was not a realistic depiction of the real world:
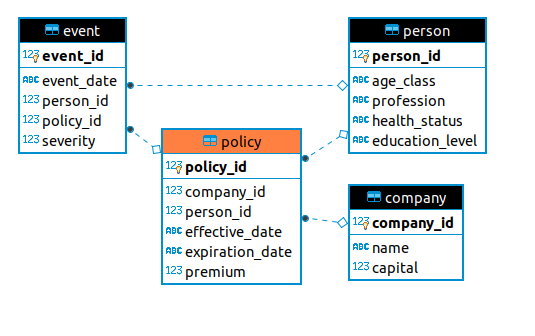
There was only one database, shared by all entities involved in the simulation – firms, people, and the environment. In business, it’s more realistic for companies to have their own internal databases, without the ability to access any other company’s database. I’ve reached point where I’ve decided that it would be difficult to add insurance operations, specifically the reporting of claims, if all entities used the same database. Therefore, I’ve decided to spend time this week setting up separate schemas for each company.
The reason why I didn’t do this earlier is because I hadn’t gone far enough in the SQLAlchemy documentation to figure out how to establish multiple metadata bases to allow each company in the simulation to access its own database. The decision I was facing last month was to either write the adverse selection demo with the knowledge I had, or to keep reading further to set things up the right way and then write about how I built nothing, but read some documentation in the hope that I’d build something later. I’d gotten tired of doing the latter one too many times, so I decided to just go for it.
This week, I was confident that I’d be able to fix the single-schema problem and add a claims reporting facility as well, so that’s what I’ll go over today.
Splitting the Database
Splitting the database involved two separate challenges:
- Defining the schema for each entity
- Rewriting the code to accept the new backend structure
This second challenge was the main motivation for updating the schema now rather than later. The more features I added to MIES, the more of them I would have to rewrite when I inevitably split the database.
First, I envisioned the database structure I wanted for each firm:
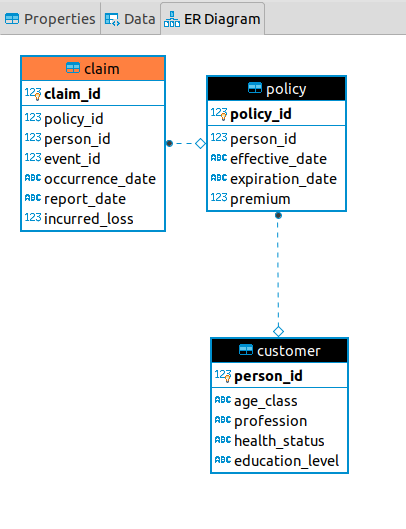
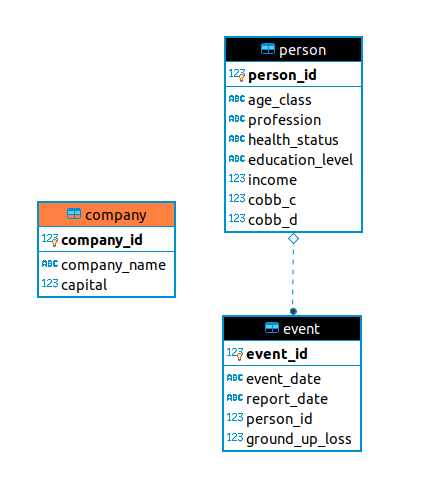
Much of this was taken from the original schema, as seen at the top of this post. The policy table contains the same information as before, minus the company id. This is because a company does not need to have this field if all of its policies belong to itself.
The customer table is new. Here, I faced the challenge of whether I wanted to maintain data integrity between the information a company knows about its own customers, and their actual attributes as they exist outside the knowledge of the firm. For example, if a person switches insurers and then changes their profession, should the original insurer know about it?
In the real world, the answer is no. This also applies to things like credit scores which can change after the company does an initial credit check. Therefore, I’ve decided to discard data integrity between companies and the environment. I may want to rethink whether I want the all-knowing environment class to at least have a canonical record of all the information in the simulation (the answer is usually yes when I write these thoughts out in a blog post).
The customer table is analogous to the person table as before, but only contains information that the firm knows about each customer. This information typically costs money to acquire when quoting policies, and is considered an underwriting expense that I will need to add later.
Lastly, I’ve added a new table for claims. I mentioned last month that since we assumed each loss was fully covered, there was no need to distinguish between losses and claims. Now that we’re facing the challenge of assigning a losses to different companies as claims, I decided to lay the groundwork now so that we can loosen this assumption when we need to. Gradually, we will see the what the differences is between a loss and a claim. A loss is a fortuitous event that happens to a person, and an insurance claim is a financial claim that a person makes against their insurer for indemnification under their policy. There is also a distinction between the loss a person endures and the loss that a company needs to pay, due to things like coverage exclusions, limits, and deductibles. The claim table will take care of many of these distinctions.
Therefore, in a two-firm simulation, we will have a database for each firm. Below, we have two ER-diagrams side-by-side for each company:
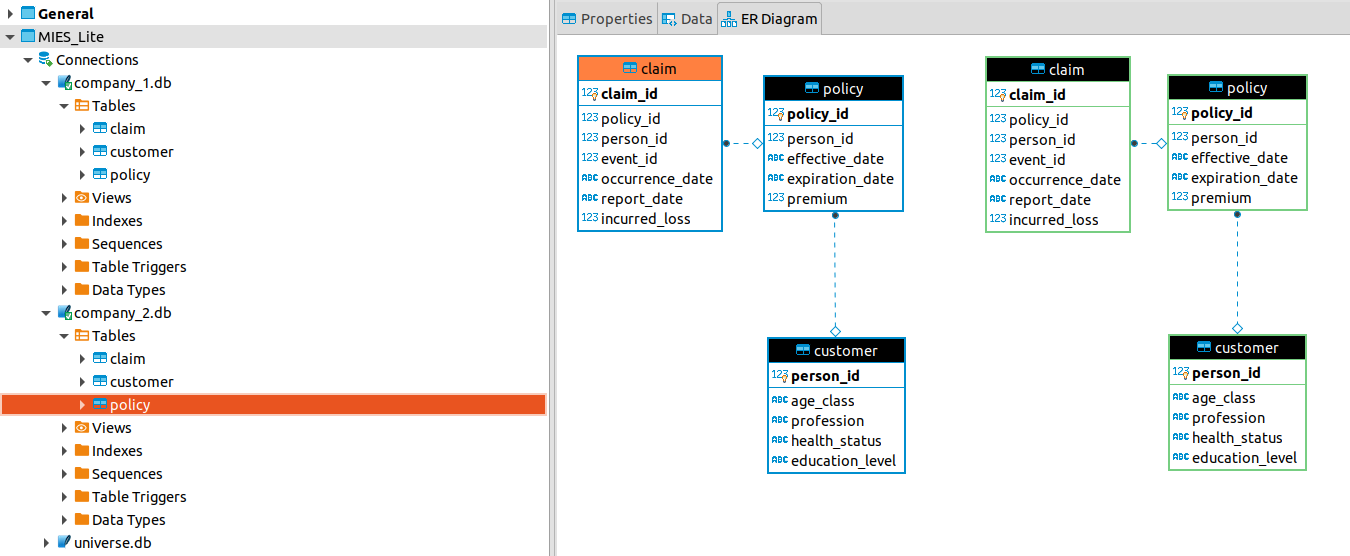
This idea carries over to the case of an n-firm simulation, where we’ll have n databases. The code that defines the firm schema now resides in a new module:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 |
from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, Date, Float, String from sqlalchemy import ForeignKey from sqlalchemy.orm import relationship Base = declarative_base() class Customer(Base): __tablename__ = 'customer' person_id = Column( Integer, primary_key=True ) age_class = Column(String) profession = Column(String) health_status = Column(String) education_level = Column(String) policy = relationship( "Policy", back_populates="customer" ) def __repr__(self): return "<Customer(" \ "age_class='%s', " \ "profession='%s', " \ "health_status='%s', " \ "education_level='%s'" \ ")>" % ( self.age_class, self.profession, self.health_status, self.education_level, ) class Policy(Base): __tablename__ = 'policy' policy_id = Column( Integer, primary_key=True ) person_id = Column( Integer, ForeignKey('customer.person_id') ) effective_date = Column(Date) expiration_date = Column(Date) premium = Column(Float) customer = relationship( "Customer", back_populates="policy" ) def __repr__(self): return "<Policy(person_id ='%s'," \ "effective_date ='%s', " \ "expiration_date='%s', " \ "premium='%s')>" % ( self.person_id, self.effective_date, self.expiration_date, self.premium ) class Claim(Base): __tablename__ = 'claim' claim_id = Column( Integer, primary_key=True ) policy_id = Column( Integer, ForeignKey('policy.policy_id') ) person_id = Column(Integer) event_id = Column(Integer) occurrence_date = Column(Date) report_date = Column(Date) incurred_loss = Column(Float) def __repr__(self): return "<Claim(policy_id ='%s'," \ "person_id ='%s', " \ "event_id='%s', " \ "occurrence_date='%s'," \ "report_date='%s'," \ "incurred_loss='%s')>" % ( self.policy_id, self.person_id, self.event_id, self.occurence_date, self.report_date, self.incurred_loss ) |
There is also a schema for the environment, which is similar to before but minus the policy-specific information:
Query Encapsulation
MIES relies on querying its databases to run the simulations. Up until now, many of these queries resided within the environment, broker, and insurer classes. The tricky thing about querying databases is that you should close the connections to them once you no longer need them. However, establishing and closing a database requires a few lines of code, and the queries themselves can be verbose as well. This can get repetitive and can lead to bugs if I forget to close a connection or make modifications to reused queries.
Therefore, I thought it would be a good idea to encapsulate them into functions. In order to do this, I created two modules in a folder called utilities that are used to connect to and then query the databases, respectively. For example, the connections file contains code to connect to either the universe (environment) database or the database for a particular company:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import sqlalchemy as sa from sqlalchemy.orm import sessionmaker import schema.universe as universe def connect_universe(): engine = sa.create_engine( 'sqlite:///db/universe.db', echo=True ) session = sessionmaker(bind=engine)() connection = engine.connect() return session, connection def connect_company(company_name): engine = sa.create_engine( 'sqlite:///db/companies/' + company_name + '.db', echo=True) session = sessionmaker(bind=engine)() connection = engine.connect() return session, connection |
You can see that you need to import some things, and also define an engine, session, and connection. That’s quite a bit of code that I don’t want to repeat every time I need to access a database.
Moving onto the queries, we likewise have code that we don’t want to repeat. For example, the query_population() function in the queries file returns the PersonTable from the environment schema as a dataframe:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import pandas as pd from schema.universe import Company, PersonTable from schema.insco import Customer, Policy from utilities.connections import ( connect_universe, connect_company) def query_population(): session, connection = connect_universe() query = session.query(PersonTable).statement population = pd.read_sql(query, connection) connection.close() return population |
Now, rather than calling all the code that we see within these functions, we can just get the information in one line, that is, query_population(). Other queries within the file access other parts of the database and return information we might want to ask about frequently:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
def query_company(): session, connection = connect_universe() companies_query = session.query(Company).statement companies = pd.read_sql( companies_query, connection ) connection.close() return companies def query_all_policies(): companies = query_company() policies = pd.DataFrame() for index, row in companies.iterrows(): company_id = row['company_id'] company_name = row['company_name'] session, connection = connect_company(company_name) query = session.query(Policy).statement policy_c = pd.read_sql( query, connection ) policy_c['company_id'] = company_id policy_c['company_name'] = company_name policies = policies.append(policy_c) connection.close() return policies def query_in_force_policies(curr_date): companies = get_company_names() in_force = pd.DataFrame() for company in companies: session, connection = connect_company(company) exp_query = session.query( Policy ).filter( Policy.expiration_date == curr_date ).statement company_in_force = pd.read_sql( exp_query, connection) in_force = in_force.append( company_in_force, ignore_index=True ) connection.close() return in_force def get_company_names(): session, connection = connect_universe() companies_query = session.query(Company.company_name).statement companies = pd.read_sql( companies_query, connection ) connection.close() return list(companies['company_name']) def get_company_ids(): session, connection = connect_universe() companies_query = session.query(Company.company_id).statement companies = pd.read_sql(companies_query, connection) connection.close() return list(companies['company_id']) def get_uninsured_ids(curr_date): population = query_population() in_force = query_in_force_policies(curr_date) uninsureds = population[~population['person_id'].isin(in_force['person_id'])]['person_id'] return uninsureds def get_customer_ids(company): session, connection = connect_company(company) id_query = session.query(Customer.person_id).statement ids = pd.read_sql(id_query, connection) return ids |
Claims Reporting
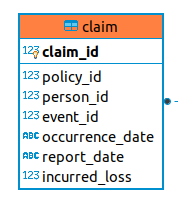
If you looked carefully, you may have noticed an additional date field added since last month. In addition to the event date, synonymous with occurrence date, we now have the report date – that is, the date the claim is reported to the insurer. This distinction has important implications in actuarial science, since different types of policies exist that may only offer coverage on claims that either occur during or are reported during the period the policy is in effect.
For now, I have assumed that all policies are written on an occurrence basis, which means that a policy covers all claims that occur within the coverage period. This means that even if an insured reports a claim several years after is has occurred and can prove that its valid and occurred during the policy period, it is still covered under the terms of the policy.
I decided to add the claims reporting facility as a method in the broker class, which now resembles more of a place where transactions happen than an actual brokerage:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
def report_claims(self, report_date): # match events to policies in which they are covered session, connection = connect_universe() event_query = session.query(Event).\ filter(Event.report_date == report_date).\ statement events = pd.read_sql(event_query, connection) connection.close() policies = query_all_policies() claims = events.merge( policies, on='person_id', how='left' ) claims = claims.query( 'event_date >= effective_date ' 'and event_date <= expiration_date' ) claims = claims.drop([ 'effective_date', 'expiration_date', 'premium', 'company_id' ], axis=1) companies = get_company_names() for company in companies: reported_claims = claims[claims['company_name'] == company] reported_claims = reported_claims.rename(columns={ 'event_date': 'occurrence_date', 'ground_up_loss': 'incurred_loss' }) reported_claims = reported_claims.drop(['company_name'], axis=1) session, connection = connect_company(company) reported_claims.to_sql( 'claim', connection, index=False, if_exists='append' ) connection.close() |
This function takes the report date as an argument, and then combs through both the event table from the environment and the policy table from each company to match the event to the appropriate company and policy, and then populate that company’s claim table.
The actual claims cycle is much more complex, involving adjusters, claimants, lawyers, agents, and other parties. These have been abstracted away for now, but I plan to add more detail later since claims modeling is itself an important part of an insurer’s strategy.
I’ve also made many changes to the other classes, but I wanted to highlight claims reporting since it’s a new feature. You can examine the other changes on GitHub.
Simulation
By encapsulating the queries, I’ve removed the number of arguments and lines of code needed to run the simulations. For example, we can now define an Insurer with just two arguments:
|
1 2 3 |
company_1 = Insurer(4000000, 'company_1') company_2 = Insurer(4000000, 'company_2') |
Whereas previously, it took five aguments:
|
1 2 3 |
company_1 = Insurer(gsession, engine, 4000000, Company, 'company_1') company_2 = Insurer(gsession, engine, 4000000, Company, 'company_2') |
The need to specify the connection, engine, and table was cumbersome and is now handled automatically by the Insurer class.
Finally, I tested out how the data flows from policy issuance to claims occurrence, and then to renewals, and MIES is still able to demonstrate the phenomenon of adverse selection:
Further Improvements
I’d like to get back to the subject of economics next week, so now I’m working on implementing the Slutsky Equation, which decomposes the motivations a consumer might have for changing their consumption as prices change.