A triangle is a data structure commonly used by actuaries to estimate reserves for insurance companies. Without going into too much detail, a reserve is money that an insurance company sets aside to pay claims on a book of policies. The reason why reserves must be estimated is due to the uncertain nature of the business – that is, for every policy sold, it is unknown at the time of sale whether or not the insured will suffer a claim over the policy period, nor is it known with certainty how many claims the insured will file, or how much the company will have to pay in order to settle those claims. Yet, the insurance company still needs to have funds available to satisfy its contractual obligations – hence, the need for actuaries.
 A triangle is a data structure commonly used by actuaries to estimate reserves for insurance companies. Without going into too much detail, a reserve is money that an insurance company sets aside to pay claims on a book of policies. The reason why reserves must be estimated is due to the uncertain nature of the business – that is, for every policy sold, it is unknown at the time of sale whether or not the insured will suffer a claim over the policy period, nor is it known with certainty how many claims the insured will file, or how much the company will have to pay in order to settle those claims. Yet, the insurance company still needs to have funds available to satisfy its contractual obligations – hence, the need for actuaries.
A triangle is a data structure commonly used by actuaries to estimate reserves for insurance companies. Without going into too much detail, a reserve is money that an insurance company sets aside to pay claims on a book of policies. The reason why reserves must be estimated is due to the uncertain nature of the business – that is, for every policy sold, it is unknown at the time of sale whether or not the insured will suffer a claim over the policy period, nor is it known with certainty how many claims the insured will file, or how much the company will have to pay in order to settle those claims. Yet, the insurance company still needs to have funds available to satisfy its contractual obligations – hence, the need for actuaries.Triangles are popular amongst actuaries because they provide a compact summarization of claims transactions, and are an elegant visual representation of claims development. They are furthermore amenable to several algorithms that are used to estimate the reserves, such as chain ladder, Bornhuetter-Ferguson, and ODP Bootstrap.
I had originally set out to do something more ambitious for today – that is, to automate the production of browser-based triangles via JavaScript, but I’m not quite there yet with my studies in the language, and moreover simply setting up pieces of the frontend involved enough work and learning to merit its own post.
Today, I’ll go over the visual presentation of actuarial triangles in HTML, while later posts will cover automating their production via JavaScript, JSON, and backend calculations.
Below, you’ll find a table of 15 claims, taken from Friedland’s text on claims reserving. The Claim ID is simply a value to identify a particular claim. The other two columns have the following definitions:
- Accident Date
- Report Date
The accident date is the date on which the claim occurs. For example, if you were driving on January 5 and had an accident during that trip, then January 5 would be the accident date.
The report date is the date on which the claim is reported to the insurer. If you were driving around on January 5 and had an accident during that trip, but didn’t notify the insurance company until February 1, then February 1 would be the report date.
You may be wondering why actuaries would care about the distinction. In the table below, you see that at worst, claims are reported only a few months after they occur. In certain lines of business, however, claims can be reported even many years after they occur. One example would be asbestos claims, in which cancer may not develop until many years after exposure to the substance. Another would be roof damage resulting from storms, in which the homeowners may not know that their roofs are damaged until the next time they climb up to go see, which may happen some time after the storm in question.
| Reported Claims | ||
|---|---|---|
| Claim ID | Accident Date | Report Date |
| 1 | Jan-5-05 | Feb-1-05 |
| 2 | May-4-05 | May-15-05 |
| 3 | Aug-20-05 | Dec-15-05 |
| 4 | Oct-28-05 | May-15-06 |
| 5 | Mar-3-06 | Jul-1-06 |
| 6 | Sep-18-06 | Oct-2-06 |
| 7 | Dec-1-06 | Feb-15-07 |
| 8 | Mar-1-07 | Apr-1-07 |
| 9 | Jun-15-07 | Sep-9-07 |
| 10 | Sep-30-07 | Oct-20-07 |
| 11 | Dec-12-07 | Mar-10-08 |
| 12 | Apr-12-08 | Jun-18-08 |
| 13 | May-28-08 | Jul-23-08 |
| 14 | Nov-12-08 | Dec-5-08 |
| 13 | Oct-15-08 | Feb-2-09 |
| 14 | Nov-12-08 | Dec-5-08 |
| 15 | Oct-15-08 | Feb-2-09 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 |
<table style="width: 500px"> <tr> <th colspan="3"><strong>Reported Claims</strong></th> </tr> <tr> <th><strong>Claim ID</strong></th> <th><strong>Accident Date</strong></th> <th><strong>Report Date</strong></th> </tr> <tr> <td>1</td> <td>Jan-5-05</td> <td>Feb-1-05</td> </tr> <tr> <td>2</td> <td>May-4-05</td> <td>May-15-05</td> </tr> <tr> <td>3</td> <td>Aug-20-05</td> <td>Dec-15-05</td> </tr> <tr> <td>4</td> <td>Oct-28-05</td> <td>May-15-06</td> </tr> <tr> <td>5</td> <td>Mar-3-06</td> <td>Jul-1-06</td> </tr> <tr> <td>6</td> <td>Sep-18-06</td> <td>Oct-2-06</td> </tr> <tr> <td>7</td> <td>Dec-1-06</td> <td>Feb-15-07</td> </tr> <tr> <td>8</td> <td>Mar-1-07</td> <td>Apr-1-07</td> </tr> <tr> <td>9</td> <td>Jun-15-07</td> <td>Sep-9-07</td> </tr> <tr> <td>10</td> <td>Sep-30-07</td> <td>Oct-20-07</td> </tr> <tr> <td>11</td> <td>Dec-12-07</td> <td>Mar-10-08</td> </tr> <tr> <td>12</td> <td>Apr-12-08</td> <td>Jun-18-08</td> </tr> <tr> <td>13</td> <td>May-28-08</td> <td>Jul-23-08</td> </tr> <tr> <td>14</td> <td>Nov-12-08</td> <td>Dec-5-08</td> </tr> <tr> <td>13</td> <td>Oct-15-08</td> <td>Feb-2-09</td> </tr> <tr> <td>14</td> <td>Nov-12-08</td> <td>Dec-5-08</td> </tr> <tr> <td>15</td> <td>Oct-15-08</td> <td>Feb-2-09</td> </tr> </table> |
There really isn’t much to it, but I did learn a few things here. In particular, the HTML attribute colspan was used on the top row header to merge the top few cells together. Furthermore, I altered a ruleset to this site’s CSS, which centered and middle-aligned the text within the table:
|
1 2 3 4 |
th, td { text-align: center; vertical-align: middle; } |
While the above table is straightforward to understand, there isn’t much that you can do with it. First, there aren’t any claim dollars attached to those claims, so we won’t be able to perform any kind of financial projections if there aren’t any historical transactions. Second, even after getting the transaction data, the presentation can get messy because the order in which transactions occur don’t always coincide with the order in which claims occur or are reported.
We see that this is the case in the table below, which shows the historical transactions for this group of claims. The first payment for claim 9 occurs before the first payment for claim 4, even though claim 4 occurred first.
| Claim Payment Transactions by Calendar Year | ||||
|---|---|---|---|---|
| Claim ID | Accident Date | Report Date | Transaction Calendar Year | Amount ($) |
| 1 | Jan-5-05 | Feb-1-05 | 2005 | 400 |
| 2 | May-4-05 | May-15-05 | 2005 | 200 |
| 1 | Jan-5-05 | Feb-1-05 | 2006 | 220 |
| 2 | May-4-05 | May-15-05 | 2006 | 200 |
| 3 | Aug-20-05 | Dec-15-05 | 2006 | 200 |
| 5 | Mar-3-06 | Jul-1-06 | 2006 | 260 |
| 6 | Sep-18-06 | Oct-2-06 | 2006 | 200 |
| 3 | Aug-20-05 | Dec-15-05 | 2007 | 300 |
| 5 | Mar-3-06 | Jul-1-06 | 2007 | 190 |
| 7 | Dec-1-06 | Feb-15-07 | 2007 | 270 |
| 8 | Mar-1-07 | Apr-1-07 | 2007 | 200 |
| 9 | Jun-15-07 | Sep-9-07 | 2007 | 460 |
| 4 | Oct-28-05 | May-15-06 | 2008 | 300 |
| 6 | Sep-18-06 | Oct-2-06 | 2008 | 230 |
| 8 | Mar-1-07 | Apr-1-07 | 2008 | 200 |
| 10 | Sep-30-07 | Oct-20-07 | 2008 | 400 |
| 11 | Dec-12-07 | Mar-10-08 | 2008 | 60 |
| 12 | Apr-12-08 | Jun-18-08 | 2008 | 400 |
| 13 | May-28-08 | Jul-23-08 | 2008 | 300 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 |
<table style="width: 500px"> <tr> <th colspan="5"><strong>Claim Payment Transactions by Calendar Year</strong></th> </tr> <tr> <th><strong>Claim ID</strong></th> <th><strong>Accident Date</strong></th> <th><strong>Report Date</strong></th> <th><strong>Transaction Calendar Year</strong></th> <th><strong>Amount ($)</strong></th> </tr> <tr> <td>1</td> <td>Jan-5-05</td> <td>Feb-1-05</td> <td>2005</td> <td>400</td> </tr> <tr> <td>2</td> <td>May-4-05</td> <td>May-15-05</td> <td>2005</td> <td>200</td> </tr> <tr> <td>1</td> <td>Jan-5-05</td> <td>Feb-1-05</td> <td>2006</td> <td>220</td> </tr> <tr> <td>2</td> <td>May-4-05</td> <td>May-15-05</td> <td>2006</td> <td>200</td> </tr> <tr> <td>3</td> <td>Aug-20-05</td> <td>Dec-15-05</td> <td>2006</td> <td>200</td> </tr> <tr> <td>5</td> <td>Mar-3-06</td> <td>Jul-1-06</td> <td>2006</td> <td>260</td> </tr> <tr> <td>6</td> <td>Sep-18-06</td> <td>Oct-2-06</td> <td>2006</td> <td>200</td> </tr> <tr> <td>3</td> <td>Aug-20-05</td> <td>Dec-15-05</td> <td>2007</td> <td>300</td> </tr> <tr> <td>5</td> <td>Mar-3-06</td> <td>Jul-1-06</td> <td>2007</td> <td>190</td> </tr> <tr> <td>7</td> <td>Dec-1-06</td> <td>Feb-15-07</td> <td>2007</td> <td>270</td> </tr> <tr> <td>8</td> <td>Mar-1-07</td> <td>Apr-1-07</td> <td>2007</td> <td>200</td> </tr> <tr> <td>9</td> <td>Jun-15-07</td> <td>Sep-9-07</td> <td>2007</td> <td>460</td> </tr> <tr> <td>4</td> <td>Oct-28-05</td> <td>May-15-06</td> <td>2008</td> <td>300</td> </tr> <tr> <td>6</td> <td>Sep-18-06</td> <td>Oct-2-06</td> <td>2008</td> <td>230</td> </tr> <tr> <td>8</td> <td>Mar-1-07</td> <td>Apr-1-07</td> <td>2008</td> <td>200</td> </tr> <tr> <td>10</td> <td>Sep-30-07</td> <td>Oct-20-07</td> <td>2008</td> <td>400</td> </tr> <tr> <td>11</td> <td>Dec-12-07</td> <td>Mar-10-08</td> <td>2008</td> <td>60</td> </tr> <tr> <td>12</td> <td>Apr-12-08</td> <td>Jun-18-08</td> <td>2008</td> <td>400</td> </tr> <tr> <td>13</td> <td>May-28-08</td> <td>Jul-23-08</td> <td>2008</td> <td>300</td> </tr> </table> |
A more visually appealing representation orders the claims chronologically by date of occurrence, while ordering the transactions horizontally by date of payment.
| Claims Transaction Paid Claims | ClaimID | AccidentDate | ReportDate | Incremental Payments in Calendar Year | ||
|---|---|---|---|---|---|---|
| 2005 | 2006 | 2007 | 2008 | |||
| 1 | Jan-5-05 | Feb-1-05 | 400 | 220 | 0 | 0 |
| 2 | May-4-05 | May-15-05 | 200 | 200 | 0 | 0 |
| 3 | Aug-20-05 | Dec-15-05 | 0 | 200 | 300 | 0 |
| 4 | Oct-28-05 | May-15-06 | 0 | 0 | 300 | |
| 5 | Mar-3-06 | Jul-1-06 | 260 | 190 | 0 | |
| 6 | Sep-18-06 | Oct-2-06 | 200 | 0 | 230 | |
| 7 | Dec-1-06 | Feb-15-07 | 270 | 0 | ||
| 8 | Mar-1-07 | Apr-1-07 | 200 | 200 | ||
| 9 | Jun-15-07 | Sep-9-07 | 460 | 0 | ||
| 10 | Sep-30-07 | Oct-20-07 | 0 | 400 | ||
| 11 | Dec-12-07 | Mar-10-08 | 60 | |||
| 12 | Apr-12-08 | Jun-18-08 | 400 | |||
| 13 | May-28-08 | Jul-23-08 | 300 | |||
| 14 | Nov-12-08 | Dec-5-08 | 0 | |||
| 15 | Oct-15-08 | Feb-2-09 | ||||
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 |
<table style="width: 500px"> <tr> <th colspan="7"><strong>Claims Transaction Paid Claims</strong></th> </tr> <th rowspan="2"><strong>Claim</br>ID</strong></th> <th rowspan="2"><strong>Accident</br>Date</strong></th> <th rowspan="2"><strong>Report</br>Date</strong></th> <th colspan="4"><strong>Incremental Payments in Calendar Year</strong></th> </tr> <tr> <th><strong>2005</strong></th> <th><strong>2006</strong></th> <th><strong>2007</strong></th> <th><strong>2008</strong></th> </tr> <tr> <td>1</td> <td>Jan-5-05</td> <td>Feb-1-05</td> <td>400</td> <td>220</td> <td>0</td> <td>0</td> </tr> <tr> <td>2</td> <td>May-4-05</td> <td>May-15-05</td> <td>200</td> <td>200</td> <td>0</td> <td>0</td> </tr> <tr> <td>3</td> <td>Aug-20-05</td> <td>Dec-15-05</td> <td>0</td> <td>200</td> <td>300</td> <td>0</td> </tr> <tr class="separated"> <td>4</td> <td>Oct-28-05</td> <td>May-15-06</td> <td></td> <td>0</td> <td>0</td> <td>300</td> </tr> <tr> <td>5</td> <td>Mar-3-06</td> <td>Jul-1-06</td> <td></td> <td>260</td> <td>190</td> <td>0</td> </tr> <tr> <td>6</td> <td>Sep-18-06</td> <td>Oct-2-06</td> <td></td> <td>200</td> <td>0</td> <td>230</td> </tr> <tr class="separated"> <td>7</td> <td>Dec-1-06</td> <td>Feb-15-07</td> <td></td> <td></td> <td>270</td> <td>0</td> </tr> <tr> <td>8</td> <td>Mar-1-07</td> <td>Apr-1-07</td> <td></td> <td></td> <td>200</td> <td>200</td> </tr> <tr> <td>9</td> <td>Jun-15-07</td> <td>Sep-9-07</td> <td></td> <td></td> <td>460</td> <td>0</td> </tr> <tr> <td>10</td> <td>Sep-30-07</td> <td>Oct-20-07</td> <td></td> <td></td> <td>0</td> <td>400</td> </tr> <tr class="separated"> <td>11</td> <td>Dec-12-07</td> <td>Mar-10-08</td> <td></td> <td></td> <td></td> <td>60</td> </tr> <tr> <td>12</td> <td>Apr-12-08</td> <td>Jun-18-08</td> <td></td> <td></td> <td></td> <td>400</td> </tr> <tr> <td>13</td> <td>May-28-08</td> <td>Jul-23-08</td> <td></td> <td></td> <td></td> <td>300</td> </tr> <tr> <td>14</td> <td>Nov-12-08</td> <td>Dec-5-08</td> <td></td> <td></td> <td></td> <td>0</td> </tr> <tr> <td>15</td> <td>Oct-15-08</td> <td>Feb-2-09</td> <td></td> <td></td> <td></td> <td></td> </tr> </table> |
I’ve picked up a few pieces of syntax here, as not only have I made use of the colspan attribute, but also the rowspan attribute, allowing the first three subheadings of the table to occupy two rows each. Furthermore, I’ve added horizontal lines to visually separate the claims by accident year, by adding a new ruleset to the site’s CSS:
|
1 2 3 4 |
tr.separated td { /* set border style for separated rows */ border-bottom: 2px solid #D8D8D8; } |
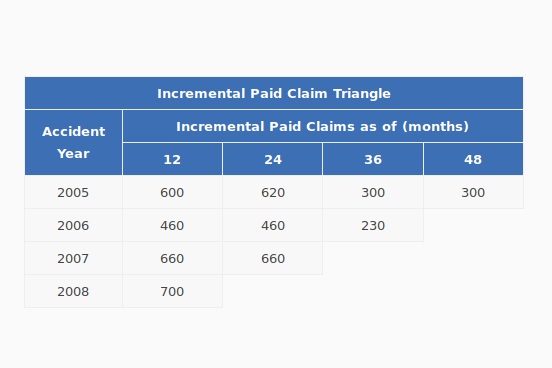
Finally, although the above table provides a better description of the book of business, it is not compact, and nor is it in a form that is amenable to reserving calculations. Below is a table that aggregates the transactions by accident year, on an incremental paid basis. Below that, is a similar table, but stated on a cumulative paid basis.
| Incremental Paid Claim Triangle | ||||
|---|---|---|---|---|
| AccidentYear | Incremental Paid Claims as of (months) | |||
| 12 | 24 | 36 | 48 | |
| 2005 | 600 | 620 | 300 | 300 |
| 2006 | 460 | 460 | 230 | |
| 2007 | 660 | 660 | ||
| 2008 | 700 | |||
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
<table style="width: 500px"> <tr> <th colspan="5"><strong>Incremental Paid Claim Triangle</strong></th> </tr> <tr> <th rowspan="2"><strong>Accident</br>Year</strong></th> <th colspan="4"><strong>Incremental Paid Claims as of (months)</strong></th> </tr> <tr> <th><strong>12</strong></th> <th><strong>24</strong></th> <th><strong>36</strong></th> <th><strong>48</strong></th> </tr> <tr> <td>2005</td> <td>600</td> <td>620</td> <td>300</td> <td>300</td> </tr> <tr> <td>2006</td> <td>460</td> <td>460</td> <td>230</td> </tr> <tr> <td>2007</td> <td>660</td> <td>660</td> </tr> <tr> <td>2008</td> <td>700</td> </tr> </table> |
| Cumulative Paid Claim Triangle | ||||
|---|---|---|---|---|
| AccidentYear | Cumulative Paid Claims as of (months) | |||
| 12 | 24 | 36 | 48 | |
| 2005 | 600 | 1,220 | 1,520 | 1,820 |
| 2006 | 460 | 920 | 1,150 | |
| 2007 | 660 | 1,320 | ||
| 2008 | 700 | |||
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
<table style="width: 500px"> <tr> <th colspan="5"><strong>Cumulative Paid Claim Triangle</strong></th> </tr> <tr> <th rowspan="2"><strong>Accident</br>Year</strong></th> <th colspan="4"><strong>Cumulative Paid Claims as of (months)</strong></th> </tr> <tr> <th><strong>12</strong></th> <th><strong>24</strong></th> <th><strong>36</strong></th> <th><strong>48</strong></th> </tr> <tr> <td>2005</td> <td>600</td> <td>1,220</td> <td>1,520</td> <td>1,820</td> </tr> <tr> <td>2006</td> <td>460</td> <td>920</td> <td>1,150</td> </tr> <tr> <td>2007</td> <td>660</td> <td>1,320</td> </tr> <tr> <td>2008</td> <td>700</td> </tr> </table> |
While I’ve got the visual representation of what I want to achieve here, there’s still quite a bit of work to do. As you can see here, there’s a lot of repetition, and hardcoded redundant values in the code. Indeed, I caught several errors prior to publishing this post. Next, I’ll aim to streamline the production of these tables via JavaScript with the following tasks:
- Store claims data as a JSON object
- Write a JavaScript function to read the JSON, construct the tables, and populate the tables
Repetition increases the chance for error – for example, you can see that I’ve repeated several bits of data such as the accident date for many of these claims. It’s better to store them in one location, perhaps as a JSON object.
The tables above took a lot of copying and pasting of HTML tags. It would be more efficient, and less error-prone, if I automated the construction of these tables with a function.
 I’ve got a few side projects going on, one of which involves creating a web application for some of the actuarial libraries I’m developing. Since I have a bad habit of quitting projects shortly after I’ve announced them to the public, I’m going to wait until I’ve made some progress on it. In the meantime, I’d like to talk about some of the tools that I’ve had to learn in order to get this done – one of which is JavaScript.
I’ve got a few side projects going on, one of which involves creating a web application for some of the actuarial libraries I’m developing. Since I have a bad habit of quitting projects shortly after I’ve announced them to the public, I’m going to wait until I’ve made some progress on it. In the meantime, I’d like to talk about some of the tools that I’ve had to learn in order to get this done – one of which is JavaScript.
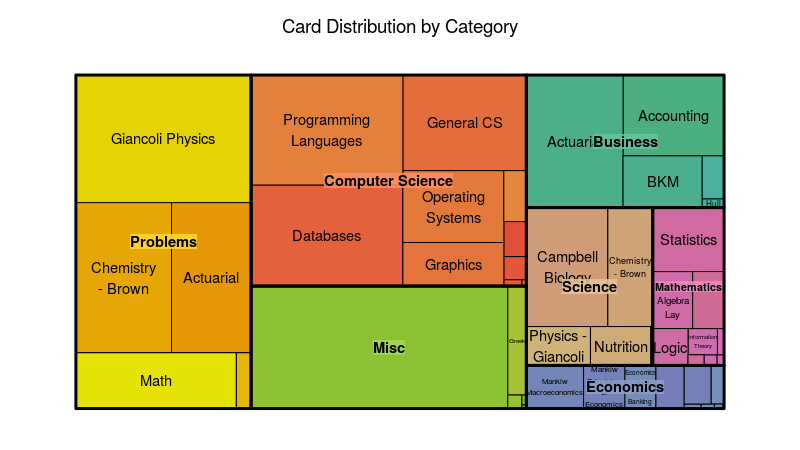
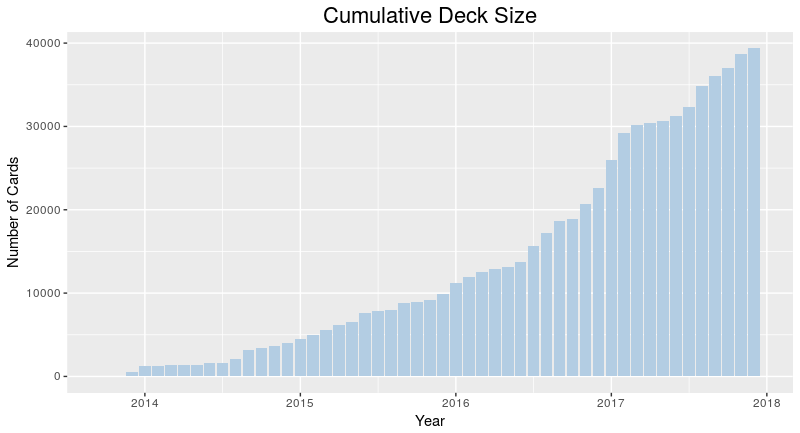
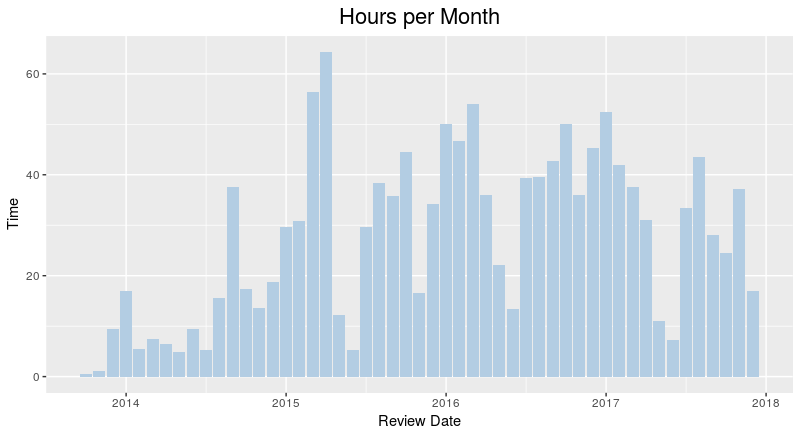
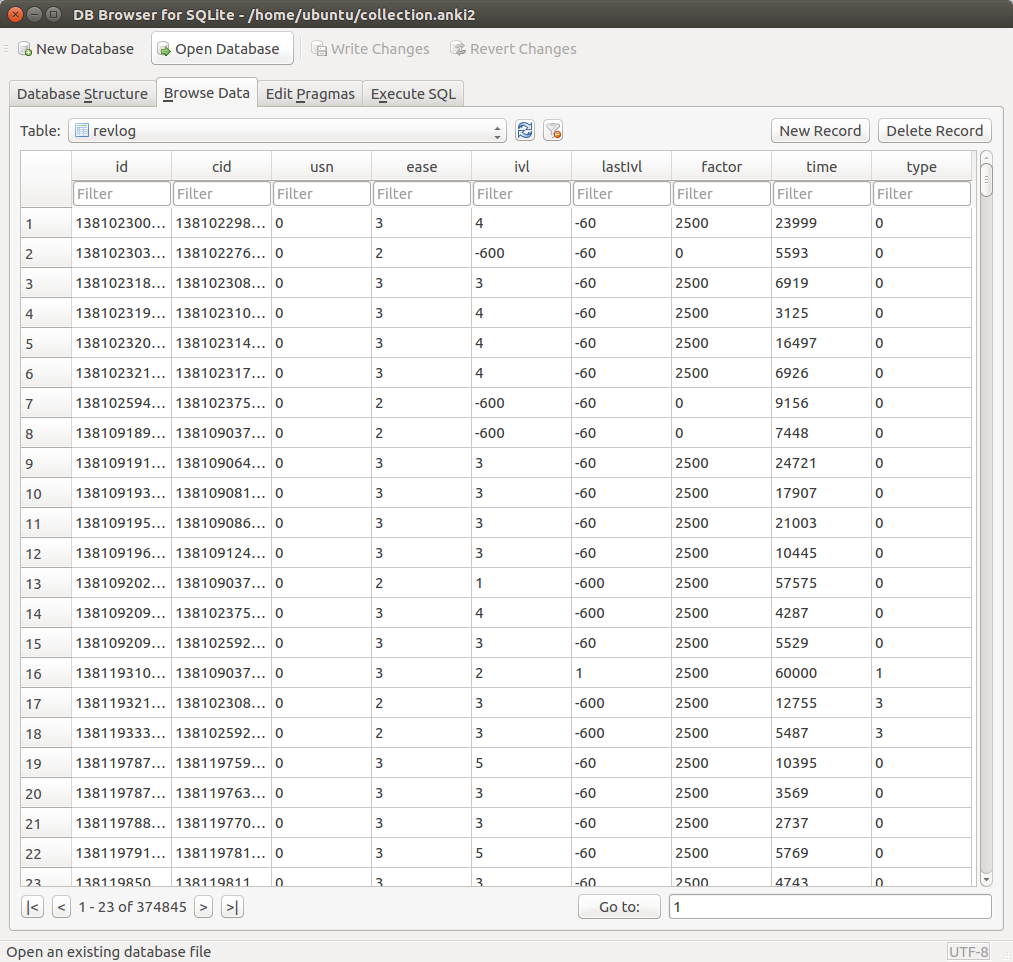
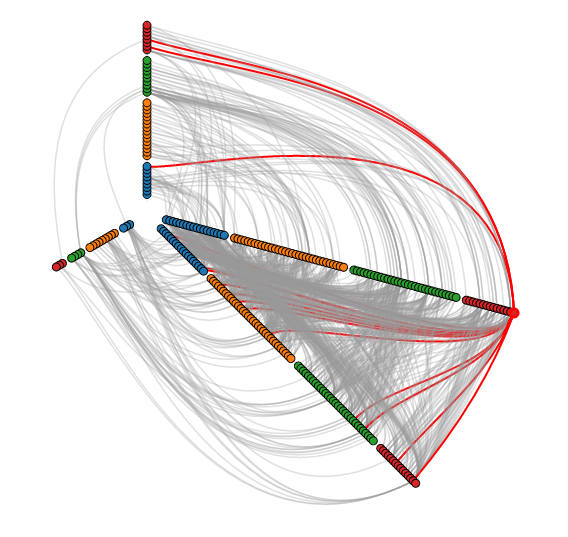 There are various layouts that you can choose from to visualize a network. All of the networks that you have seen so far have been drawn with a force-directed layout. However, one weakness that you may have noticed is that as the number of nodes and edges grows, the appearance of the graph looks more and more like a hairball such that there’s so much clutter that you can’t identify any meaningful patterns.
There are various layouts that you can choose from to visualize a network. All of the networks that you have seen so far have been drawn with a force-directed layout. However, one weakness that you may have noticed is that as the number of nodes and edges grows, the appearance of the graph looks more and more like a hairball such that there’s so much clutter that you can’t identify any meaningful patterns.