MIES, standing for Miniature Insurance Economic Simulator, is a side project of mine that was originally conceived in 2013. The goal of MIES is to create a realistic, but simplified representation of an insurance company ERP, populate it with simulated data, and from there use it to test economic and actuarial theories found in academic literature. From this template, multiple firms can then be created, which can then be used to test inter-firm competition, the effects of which will be manifested via the simulated population of insureds.
Inspiration for the project came from the early days of my career, when I was first learning how to program computers. While I found ample general-purpose material online for popular languages such as Python, R, and SQL, little existed as far as insurance-specific applications. Likewise, from an insurance perspective, plenty of papers were available from the CAS, but they were mostly theoretical in nature and lacked the practical aspects of using numerical programming to conduct actuarial work – i.e., using SQL to pull from databases, what a typical insurance data warehouse looks like, how to build a pricing model with R, etc.
I had hoped to bridge that gap by creating a mock-up of an insurance data warehouse that could be used to practice SQL queries against, thus bridging the gap between theory and practice, and creating a resource that other actuaries and students could use to further their own education. I then realized that not only would I be able to simulate a single company’s operations, but I’d also be able to simulate firm interactions by cloning the database template and deploying competing firm strategies against each other. And furthermore, should I succeed in creating a robust simulation engine, I would be able to incorporate and test open source actuarial libraries written by others.
I would have liked to introduce this project later, but I figured if I were to reveal pieces of the project (like I did with the last post) without an overarching framework, readers wouldn’t really get the point of what I was trying to achieve. Back in 2013, the project stalled due to exams, and my lack of technical knowledge and insurance experience. Now that I’ve worked for a bit and finished my exams, I can continue work on this more regularly. Below, I present a high-level schematic of the MIES engine:
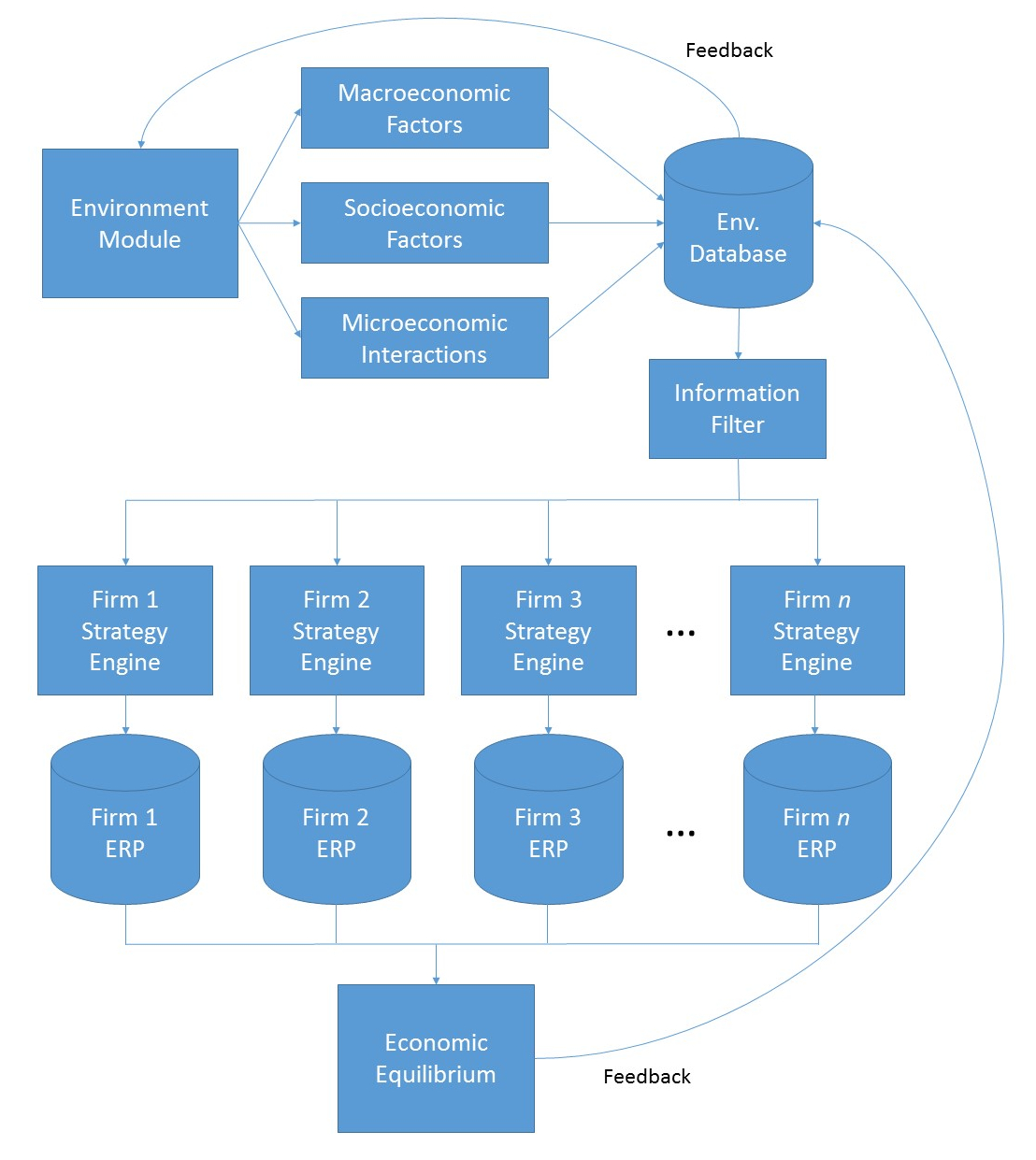
The image above displays two of the three layers of the engine – an environment layer that is used to simulate the world in which firms and the individuals they hope to insure interact, and a firm layer that stores each firm’s ERP and corporate strategy.
- Environment Layer
- Firm Layer
The environment layer simulates the population of potential insureds who are subject to everyday perils that insurance companies hope to insure. The environment module will be a program (or collection of programs) that provides the macroeconomic (GDP, unemployment, inflation), microeconomic (individual wealth, utility curves, births and deaths), sociodemographic (race, religion, household income, commute time), and other environmental parameters such as weather, to represent everyday people and the challenges they face. The simulated data are stored in a database (or a portion of a very large database) called the environmental database.
A module called the information filter then reads the environmental data and filters out information that can’t be seen by individual firms. Firms try to get as much data as they can about their potential customers, but they won’t be able to know everything about them. Therefore, firms act on incomplete information, and the information filter is designed to remove information that companies can’t access.
The firm layer is a collection of firm strategies – each of which is a program that represents the firm’s corporate strategy (pricing, reserving, marketing, claims, human resources, etc.), along with a set of firm ERPs which store the information resulting from each firm’s operations (premiums, claims, financial statements, employees).
The environment layer then simulates policies written and claims incurred, which are then stored in their respective firm’s ERPs. The result of all this is a set of economic equilibria – that is, insurance market prices, adequacy, availability, etc. Information generated from both the environment and firm layers are then fed back into the environment module as a form of feedback that influences the next iteration’s simulation.
The image below represents a simple breakdown of an individual firm ERP:
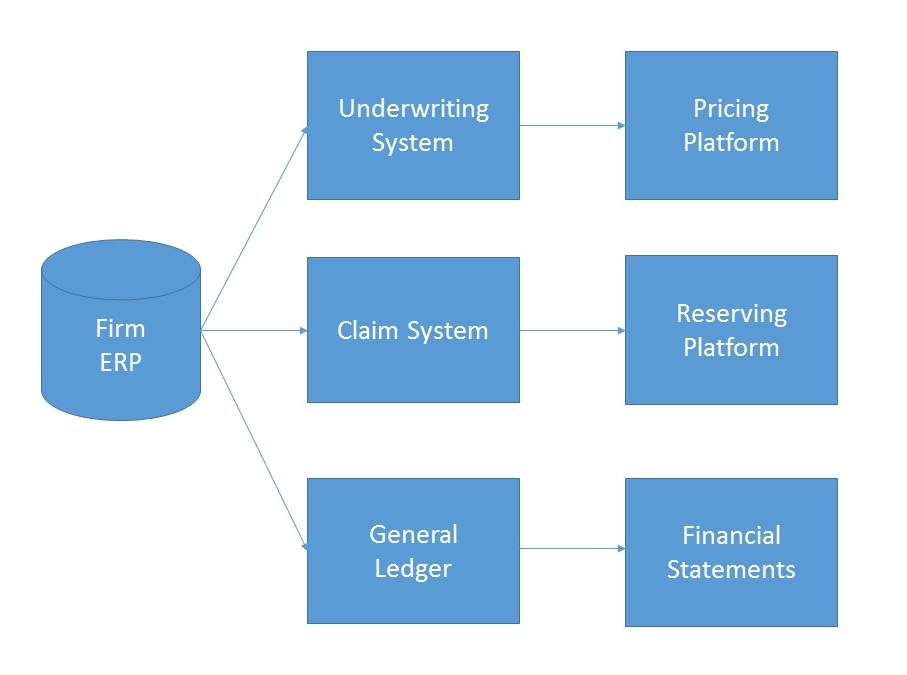
Here, we have the third layer of MIES – the user interface layer.
- Underwriting System
- Claims System
- General Ledger
An underwriting system is a platform that an insurer uses to write policies. I’ll try my best to use an available open-source engine for this (possibly openunderwriter). The frontend will be visible if a human actor is involved, otherwise, it will be driven behind the scenes programmatically.
A claims system is a platform that an insurer uses to manage and settle insurance claims. On top of the claims system is the actuarial reserving interface (triangles).
The general ledger stores accounting information that is used to produce financial statements. Current candidates for this system include ledger-cli and LedgerSMB.
Below, is a rudimentary claims database schema, containing primary-foreign key relationships, but no other attributes (to be added later):
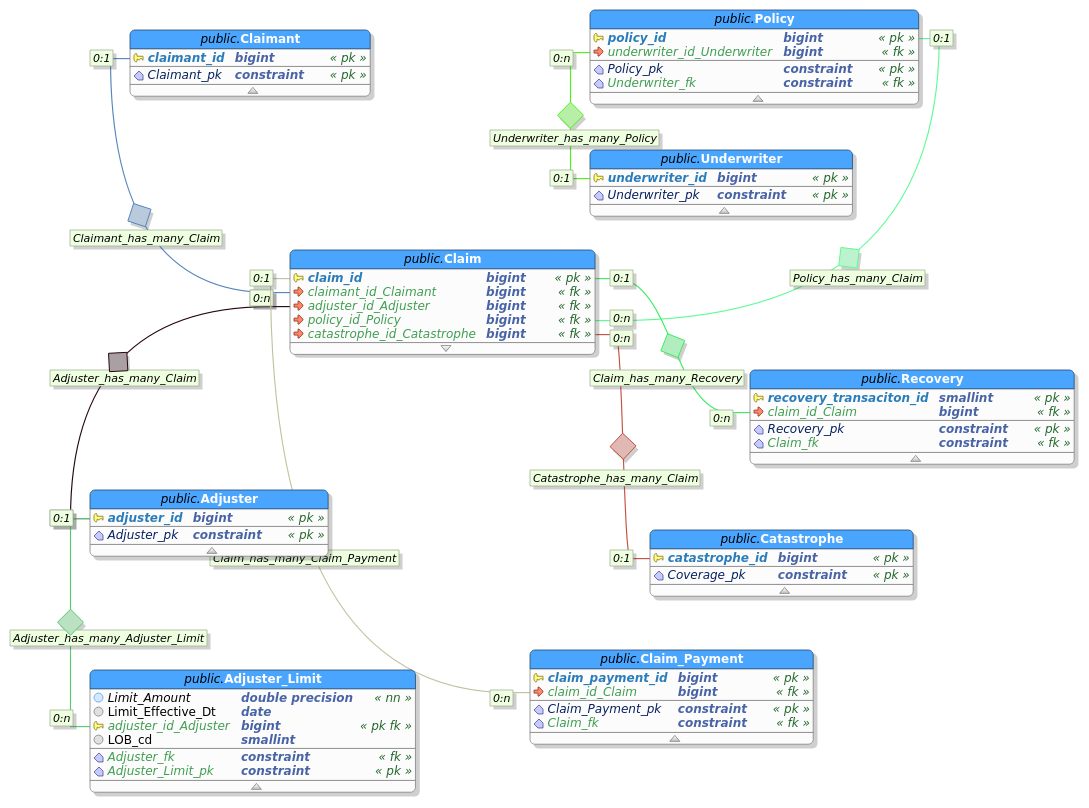
I’m using PostgreSQL for the database system, and MIES itself will be hosted on my AWS cloud account as a web-based application. I’m currently exploring Apache and serverless options as a host. The MIES engine itself was originally being scripted in Scala (I was really into Spark at the time) but will now be done in Python to reach a wider audience (I may revisit Scala if the data becomes big – hopefully I’ll be able to get some kind of funding for hosting fees if that happens).
With this ecosystem, I aim to reconcile micro- and macroeconomic theory, and study the effects of firm competition, oligopoly, and bankruptcy on the well-being of insureds. The engine will serve as the basis for other actuarial libraries and will incorporate pricing, reserving, and ERP systems that could eventually become standalone open-source applications for the insurance industry. Stay tuned for updates, and check the github repo regularly to see the project progress.