This entry is part of a series dedicated to MIES – a miniature insurance economic simulator. The source code for the project is available on GitHub.
Current Status
This week, I’ve been continuing my work on incorporating risk into the consumer behavior component of MIES. The next step in this process involves the concept of intertemporal choice, an interpretation of the budget constraint problem whereby a consumer can shift consumption from one time period to another by means of savings and loans. The content of this post follows chapter 10 of Varian.
For example, a person can consume more in a future period by saving money. A person can also increase their consumption today by taking out a loan, which comes at a cost of future consumption because they have to pay interest. When making decisions between current and future consumption, we also have to think about time value of money. When I was reading through Varian, I was happy to see that many of the concepts I learned from the financial mathematics actuarial exam were also discussed by Varian – such as bonds, annuities, and perpetuities – albeit in much less detail.
This inspired me to create a new repo to handle time value of money computations, which is not yet ready for its own series of posts, but for which you can see the initial work here. I had intended to make this repo further out in the future, but I got excited and started early.
Also relevant, is the concept of actuarial communication. Now that I’m blogging more about actuarial work, I will need to be able to write the notation here. There are some  packages that can render actuarial notation, such as actuarialsymbol. Actuaries are still in the stone age when it comes to sharing technical work over the Internet, not out of ignorance, since many actuaries are familiar with , but out of corporate inertia in getting the right tools at work (which I can suppose be due to failure to persuade the right people) and lack of momentum and willingness as many people simply just try to make do with using ASCII characters to express mathematical notation. I think this is a major impediment to adding rigor to practical actuarial work, which many young analysts complain about when they first start working, as they notice that spreadsheet models tend to be a lot more dull than what they see on the exams.
packages that can render actuarial notation, such as actuarialsymbol. Actuaries are still in the stone age when it comes to sharing technical work over the Internet, not out of ignorance, since many actuaries are familiar with , but out of corporate inertia in getting the right tools at work (which I can suppose be due to failure to persuade the right people) and lack of momentum and willingness as many people simply just try to make do with using ASCII characters to express mathematical notation. I think this is a major impediment to adding rigor to practical actuarial work, which many young analysts complain about when they first start working, as they notice that spreadsheet models tend to be a lot more dull than what they see on the exams.
I was a bit anxious in trying to get the actuarialsymbol package working since, although I knew how to get it working on my desktop, I wasn’t sure if it would work with WordPress or Anki, a study tool that I use. Fortunately, it does work! For example, the famous annuity symbol can be rendered with the command \ax{x:\angln}:

That was easy. There’s no reason why intraoffice email can’t support this, so I hope that it encourages you to pick it up as well.
The Statics Module
Up until now, testing new features has been cumbersome since many of the previous demos I have written about required existing simulation data. That is, in order to test things like intertemporal choice, I would first need to set up a simulation, run it, and then use the results as inputs into the new functions, classes, or methods.
That really shouldn’t be necessary, especially since many of the concepts I have been making modules for apply to economics in general, and not just to insurance. To solve this problem, I created the statics module, which is named after the process of comparative statics, which examines how behavior changes when an exogenous variable in the model changes (aka all the charts I’ve been making about MIES).
The statics module currently has one class, Consumption, which can return attributes such as the optimal consumption of a person given a budget and utility function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
# used for comparative statics import plotly.graph_objects as go from plotly.offline import plot from econtools.budget import Budget from econtools.utility import CobbDouglas class Consumption: def __init__( self, budget: Budget, utility: CobbDouglas ): self.budget = budget self.income = self.budget.income self.utility = utility self.optimal_bundle = self.get_consumption() self.fig = self.get_consumption_figure() def get_consumption(self): optimal_bundle = self.utility.optimal_bundle( p1=self.budget.good_x.adjusted_price, p2=self.budget.good_y.adjusted_price, m=self.budget.income ) return optimal_bundle def get_consumption_figure(self): fig = go.Figure() fig.add_trace(self.budget.get_line()) fig.add_trace(self.utility.trace( k=self.optimal_bundle[2], m=self.income / self.budget.good_x.adjusted_price * 1.5 )) fig.add_trace(self.utility.trace( k=self.optimal_bundle[2] * 1.5, m=self.income / self.budget.good_x.adjusted_price * 1.5 )) fig.add_trace(self.utility.trace( k=self.optimal_bundle[2] * .5, m=self.income / self.budget.good_x.adjusted_price * 1.5 )) fig['layout'].update({ 'title': 'Consumption', 'title_x': 0.5, 'xaxis': { 'title': 'Amount of ' + self.budget.good_x.name, 'range': [0, self.income / self.budget.good_x.adjusted_price * 1.5] }, 'yaxis': { 'title': 'Amount of ' + self.budget.good_y.name, 'range': [0, self.income * 1.5] } }) return fig def show_consumption(self): plot(self.fig) |
A lot of the code here is the same as that which can be found in the Person class. However, instead of needing to instantiate a person to do comparative statics, I can just use the Consumption class directly from the statics module. This should make creating and testing examples much easier.
Since much of the code in statics is the same as in the Person class, that gives me a hint that I can make things more maintainable by refactoring the code. I would think the right thing to do is to have the Person class use the Consumption class in the statics module, rather than the other way around.
The Intertemporal Class
The intertemporal budget constraint is:
![\[c_1 + c_2/(1+r) = m_1 + m_2/(1+r)\]](https://genedan.com/wp-content/ql-cache/quicklatex.com-9a6fd6a3e2ebfef82029195df3c17dd1_l3.png "Rendered by QuickLaTeX.com")
Note that this has the same form as the endowment budget constraint:
![\[p_1 x_1 + p_2 x_2 = p_1 m_1 + p_2 m_2 \]](https://genedan.com/wp-content/ql-cache/quicklatex.com-cb036f53f8598d33810de11d63b3a280_l3.png "Rendered by QuickLaTeX.com")
With the difference being that the two endowment goods are now replaced by consumption in times 1 and 2, represented by the  s and the prices, the
s and the prices, the  s are now replaced by discounted unit prices. The subscript 1 represents the current time and the subscript 2 represents the future time, with the price of future consumption being discounted to present value via the interest rate,
s are now replaced by discounted unit prices. The subscript 1 represents the current time and the subscript 2 represents the future time, with the price of future consumption being discounted to present value via the interest rate,  .
.
The consumer can shift consumption between periods 1 and 2 via saving and lending, subject to the constraint that the amount saved during the first period cannot exceed their first period income, and the amount borrowed during the first period cannot exceed the present value of the income of the second period.
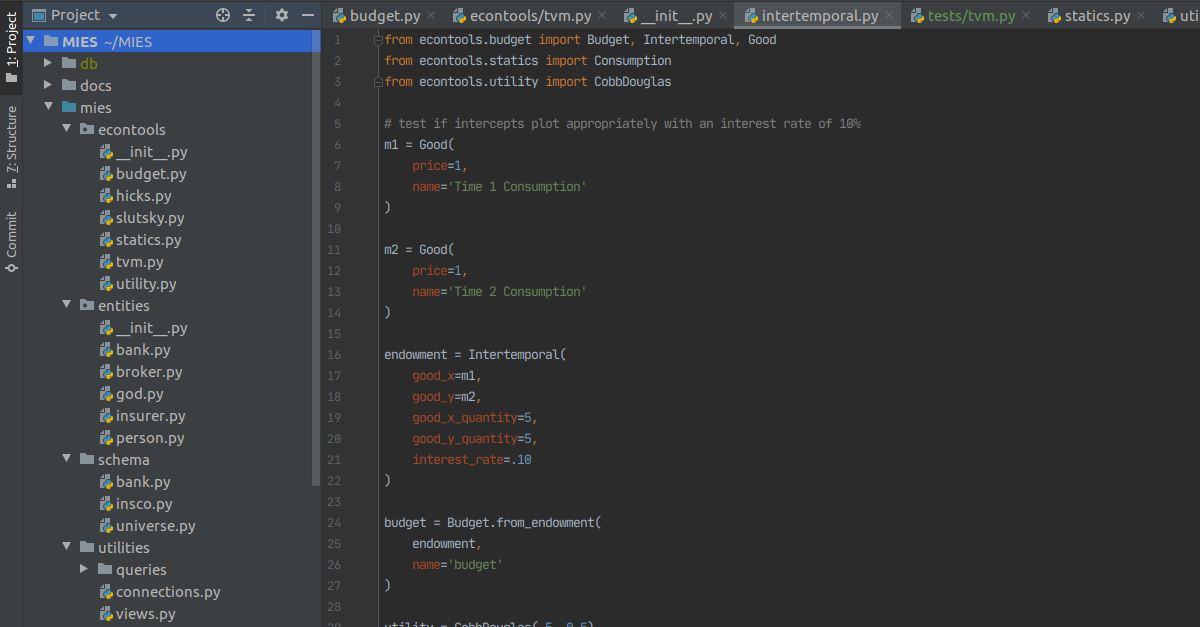
Since the intertemporal budget constraint is a form of the endowment constraint, we can modify the Endowment class in MIES to accommodate this type of consumption. I have created a subclass called Intertemporal that inherits from the Endowment class:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
class Intertemporal(Endowment): def __init__( self, good_x: Good, good_y: Good, good_x_quantity: float, good_y_quantity: float, interest_rate: float = 0, inflation_rate: float = 0 ): Endowment.__init__( self, good_x, good_y, good_x_quantity, good_y_quantity, ) self.interest_rate = interest_rate self.inflation_rate = inflation_rate self.good_y.interest_rate = self.interest_rate self.good_y.inflation_rate = self.inflation_rate |
The main difference here is that the Intertemporal class can accept an interest rate and an inflation rate to adjust the present value of future consumption.
Example
As an example, suppose we have a person who makes 5 dollars in each of time periods 1 and 2. The market interest rate is 10% and their utility function takes the Cobb Douglas form of:
![\[u(x_1, x_2) = x_1^{.5} x_2^{.5}\]](https://genedan.com/wp-content/ql-cache/quicklatex.com-9891c1cbdb32f9cfc0de926a4d5f2401_l3.png "Rendered by QuickLaTeX.com")
which means they will spend half of the present value of the endowment as consumption in period 1:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
from econtools.budget import Budget, Intertemporal, Good from econtools.statics import Consumption from econtools.utility import CobbDouglas # test if intercepts plot appropriately with an interest rate of 10% m1 = Good(price=1, name='Time 1 Consumption') m2 = Good(price=1, name='Time 2 Consumption') endowment = Intertemporal( good_x=m1, good_y=m2, good_x_quantity=5, good_y_quantity=5, interest_rate=.10 ) budget = Budget.from_endowment(endowment, name='budget') utility = CobbDouglas(.5, 0.5) consumption = Consumption(budget=budget, utility=utility) consumption.show_consumption() |
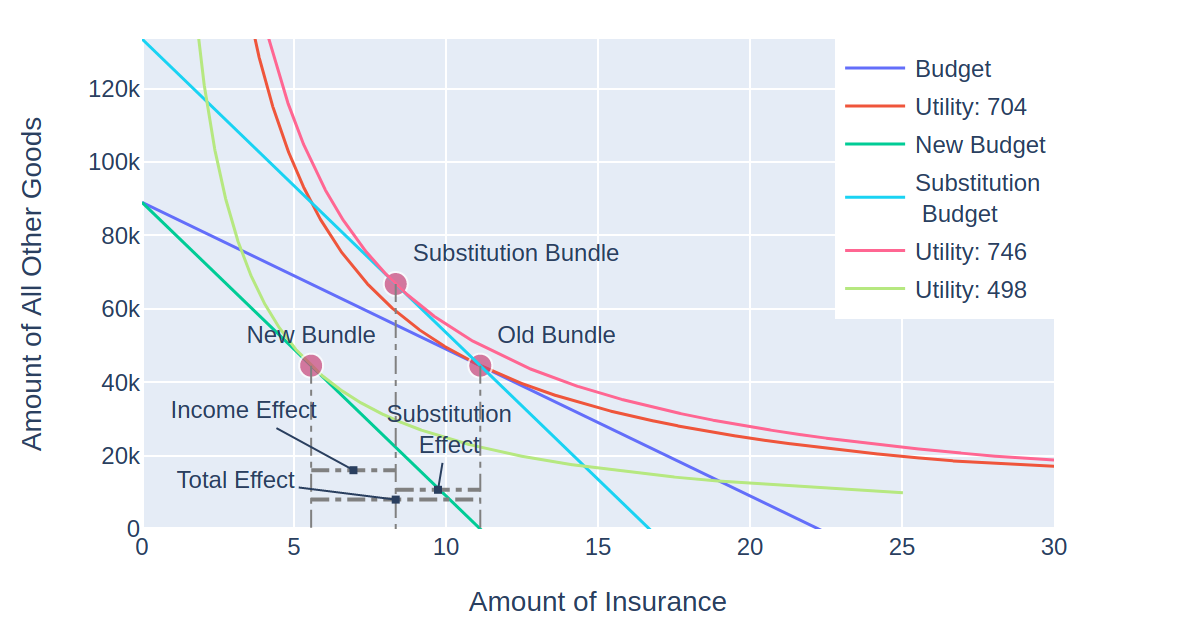
The main thing that sticks out here is that the slope of the budget constraint has changed to reflect the adjustment of income to present value. The x-axis intercept is slightly less than 10 because the present value of income is slightly less than 10, and the y-axis intercept is slightly more than 10 because if a person saved all of their time 1 income, they would receive interest of 5 * .1 = .5, making maximum consumption in period 2 10.5.
Since the person allocates half of the present value of the endowment to time 1 consumption, this means they will spend (5 + 5/1.1) * .5 = 4.77 in period one, saving 5 – 4.77 = .23, which then grows to .23 * (1 + .1) = .25 in period 2, which allows for a time 2 consumption of 5 + .25 = 5.25. This is verified by calling the optimal_bundle() method of the Consumption class:
|
1 2 |
consumption.optimal_bundle Out[7]: (4.7727272727272725, 5.25, 5.005678593539359) |
Further Improvements
The Varian chapter on intertemporal choice briefly explores present value calculations for various payment streams, such as bonds and perpetuities. I first made a small attempt at creating a tvm module, but quickly realized that the subject of time value of money is much more complex than what is introduced in Varian, since I know that other texts go further in depth, and hence it may be necessary to split a new repo off from MIES so that it can be distributed separately. This repo is called TmVal, the early stages of which I have uploaded here.
Neither of these are ready for demonstration, but you can click on the links if you are interested in seeing what I have done. The next chapter of Varian covers asset markets, which at first glance seems to just be some examples of economic models, so I’m not sure if it has any features I would like to add to MIES. There is still more work to be done on refactoring the code, so I may do that, or move further into risk aversion, or do some more work on TmVal.
![\[\frac{\Delta x_1}{\Delta p_1} = \frac{\Delta x_1^s}{\Delta p_1} - \frac{\Delta x_1^m}{\Delta m}x_1\]](https://genedan.com/wp-content/ql-cache/quicklatex.com-267df81a1e9f4fd29a64d1fdaf119964_l3.png "Rendered by QuickLaTeX.com")
 represents the quantity of good 1 (in this case insurance),
represents the quantity of good 1 (in this case insurance),  represents the price of insurance (that is, the premium) and
represents the price of insurance (that is, the premium) and  represents the consumer’s income. The deltas are used to describe how the quantity of insurance purchased changes with premium, expressed on the left side of the identity. The first term after the equals sign represents the substitution effect, and the second term after the equals sign represents the income effect.
represents the consumer’s income. The deltas are used to describe how the quantity of insurance purchased changes with premium, expressed on the left side of the identity. The first term after the equals sign represents the substitution effect, and the second term after the equals sign represents the income effect. ):
):![\[\Delta x_1 = \Delta x_1^s + \Delta x_1^n\]](https://genedan.com/wp-content/ql-cache/quicklatex.com-7b29a37678e0e5699894f293d45692e6_l3.png "Rendered by QuickLaTeX.com")
![\[\Delta m = x_1 \Delta p_1\]](https://genedan.com/wp-content/ql-cache/quicklatex.com-31da15f60d083e8875f089826d8cb193_l3.png "Rendered by QuickLaTeX.com")
![\[m^\prime = \frac{\bar{u}}{\left(\frac{c}{c +d}\frac{1}{p_1^\prime}\right)^c\left(\frac{d}{c+d}\frac{1}{p_2}\right)^d}\]](https://genedan.com/wp-content/ql-cache/quicklatex.com-7b6922ae6c1c86720257822287c6dbc6_l3.png "Rendered by QuickLaTeX.com")
 is the adjusted income, and
is the adjusted income, and  is the new premium, and
is the new premium, and  is the utility fixed at the original level.
is the utility fixed at the original level.
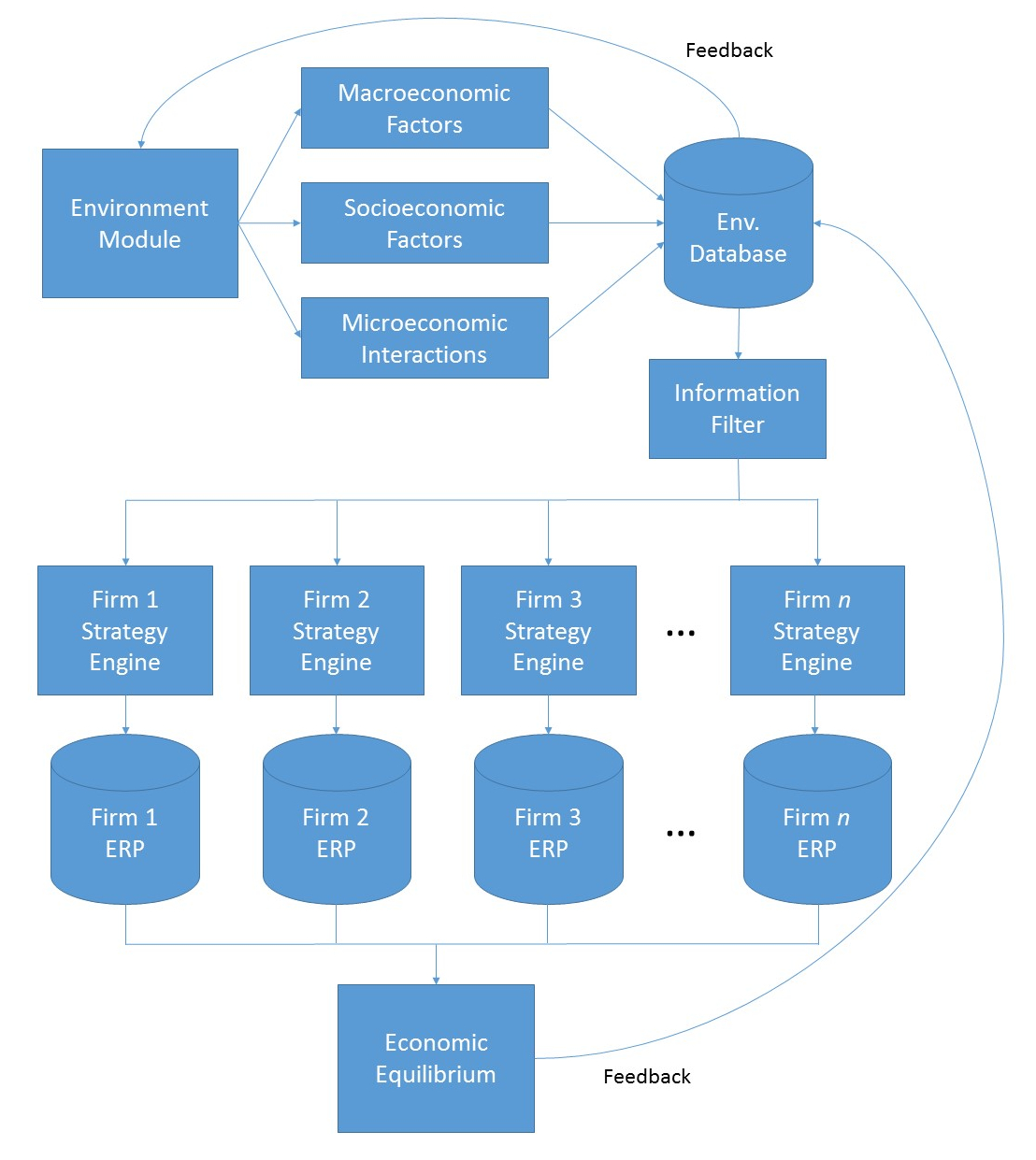
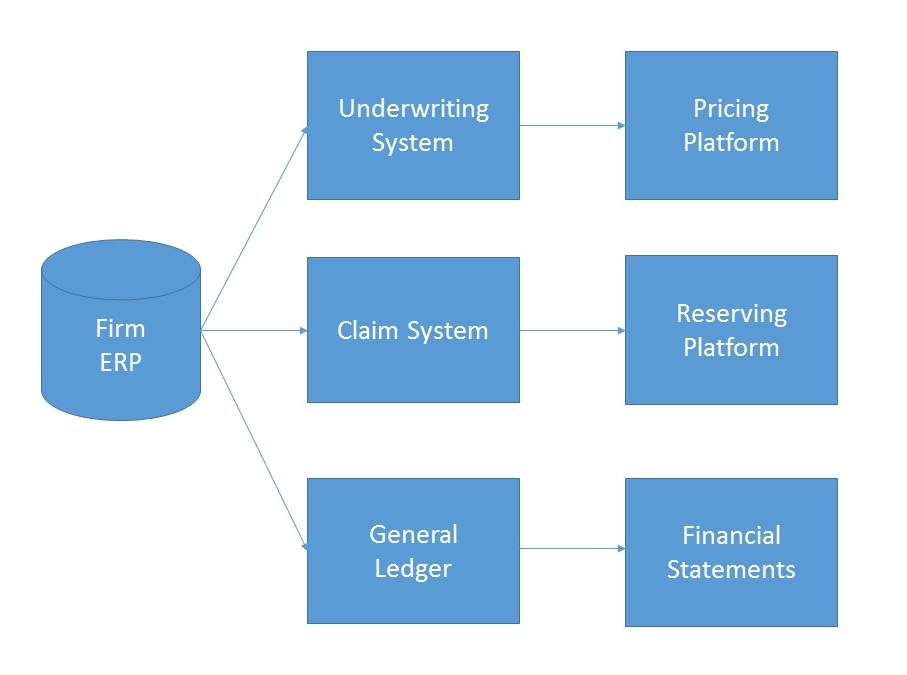
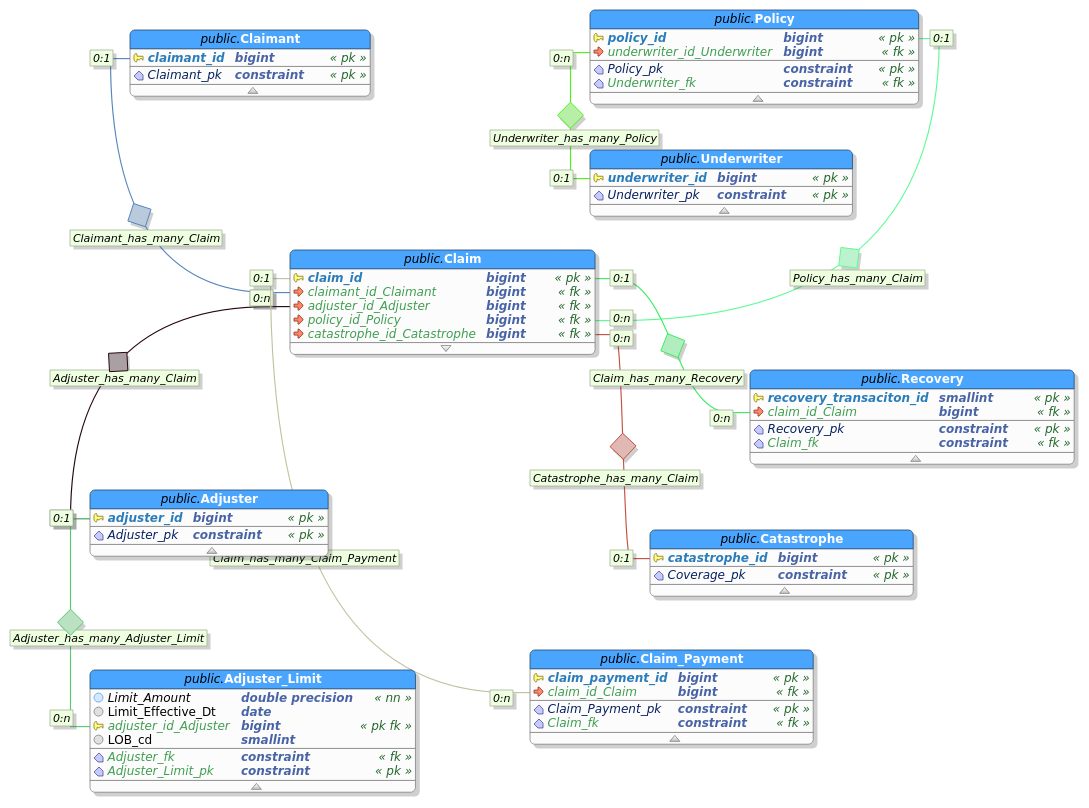 MIES, standing for Miniature Insurance Economic Simulator, is a side project of mine that was originally conceived in 2013. The goal of MIES is to create a realistic, but simplified representation of an insurance company ERP, populate it with simulated data, and from there use it to test economic and actuarial theories found in academic literature. From this template, multiple firms can then be created, which can then be used to test inter-firm competition, the effects of which will be manifested via the simulated population of insureds.
MIES, standing for Miniature Insurance Economic Simulator, is a side project of mine that was originally conceived in 2013. The goal of MIES is to create a realistic, but simplified representation of an insurance company ERP, populate it with simulated data, and from there use it to test economic and actuarial theories found in academic literature. From this template, multiple firms can then be created, which can then be used to test inter-firm competition, the effects of which will be manifested via the simulated population of insureds.